TikTok for Text! 라이너 앱 Session-based Recommender 구축기
안녕하세요. 머신러닝 엔지니어 에디입니다🙂
올해 1분기, 라이너 앱과 웹에 대대적인 변화가 있었습니다. 사람들의 정보 탐색과 정보 소비를 혁신시키기 위해 하이라이팅 유틸리티에서 벗어나 추천・검색을 중심으로 프로덕트를 개편한 것인데요. 이번 글에서는 달라진 라이너 앱에 새로 도입된 추천 기술에 대한 소개를 드리려고 합니다.
UX를 개편하면서 이제 라이너 앱을 사용하는 유저들은 화면을 아래 위로 넘기면서 추천된 콘텐츠들을 소비할 수 있게 되었습니다. 이를 통해 저희는 유저들이 앱에서 읽고 싶은 콘텐츠를 빠르게 탐색하고 콘텐츠를 더 많이 수집하기를 기대했습니다. 그리고 이 과정에서 유저의 행동에 따라 추천 콘텐츠 주제가 점점 모아지는 경험을 제공해주고 싶었습니다. 틱톡, 쇼츠, 릴스와 같은 대부분의 숏폼에서 유저가 오래 머무른 콘텐츠와 비슷한 콘텐츠들이 이어서 나오는 것처럼 말이죠.
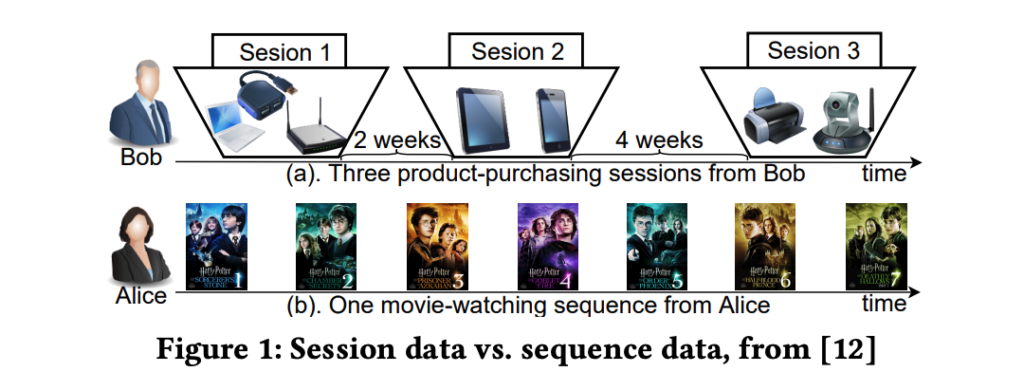
그에 따라 세션 내에서 유저의 단기 관심사를 뽑아내 개인화 경험을 제공해 줄 수 있는 세션 기반 추천 모델이 필요해졌습니다. 세션 기반 추천 모델은 시간에 따라 변하는 유저의 관심사를 고려해 추천을 해준다는 점에서, 앞서 Sequential Recommenders: 기계들과 회로들에서 새미가 소개해주신 시퀀셜 추천 모델과 유사합니다. 다만 시퀀셜 추천 모델이 유저의 Long-term 히스토리를 기반으로 유저가 좋아할만한 콘텐츠를 제공해준다면, 세션 기반 추천 모델은 한 세션 내에서 발생한 인터랙션 히스토리만을 이용해서 유저의 Short-term 관심사를 반영해준다는 데에서 차이가 있습니다.
추천시스템에서 Implicit Feedback의 활용
제가 세션 기반 추천 모델을 구상하면서 들었던 가장 큰 고민은 어떤 Explicit/Implicit feedback들을 활용할 수 있을지에 관한 것입니다. 라이너의 추천 시스템을 구성하고 있는 기존의 Retrieval 모델들은 유저의 콘텐츠 수집(하이라이트, 저장) 이력을 Input으로 받고 있습니다. 그러나 하이라이트, 저장과 같은 액션은 하나의 세션 내에선 자주 일어나지 않습니다. 따라서 이렇게 허들이 상대적으로 높은 Explicit feedback 데이터만으로 유저의 단기 관심사를 뽑아내는 것은 무리가 있습니다. 수집 외에 클릭 액션을 또 하나의 Explicit feedback으로 보고 추천에 반영한다고 해도 여전히 희소성 문제는 존재합니다.
결국 세션 내에서 유저가 발생시키는 다양한 Implicit feedback들을 수집해서 실시간으로 모델에 넣어줘야 한다는 생각이 들었습니다. 저는 평소 뉴스 추천이 라이너의 웹 콘텐츠 추천과 비슷하다는 생각을 많이 했었습니다. 둘 다 텍스트 데이터를 기반으로 하고 있을 뿐만 아니라 매일 수많은 아이템들이 새롭게 추가된다는 점에서 말입니다. 그래서 뉴스 콘텐츠에 대한 세션 기반 추천 모델 위주로 리서치를 진행하던 중에, “Positive, Negative, and Neutral: Modeling Implicit Feedback in Session-based News Recommendation” (SIGIR ’22)이라는 논문을 읽게 되었습니다. 논문에서 저자들은 다음과 같은 질문들을 던집니다.
- 유저가 뉴스를 클릭했다면, 과연 그 뉴스를 좋아했다는 뜻일까?
- 유저가 뉴스를 클릭하지 않았다면, 과연 그 뉴스를 싫어했다는 뜻일까?
- 유저와 뉴스에 대한 시간적 정보를 세션 기반 추천 모델에 반영할 수 있을까?
이어서 유저의 선호도를 모델링하기 위한 여러 Implicit feedback들을 정의하는데요. 유저가 뉴스 콘텐츠에 머무른 시간, 뉴스가 유저에게 노출됐는지 여부, 세션이 시작된 시각과 뉴스가 게시된 시각을 각각 Positive, Negative, Neutral implicit feedback으로 활용하여 유저가 다음에 클릭할만한 뉴스를 추천합니다.
논문에서는 세션 기반 추천에서 Implicit feedback 활용의 중요성을 강조합니다. 마침 저도 Explicit feedback의 한계를 느끼고 다양한 Implicit feedback들을 모델에 투입하고 싶었는데, 비슷한 문제를 해결한 레퍼런스를 찾게 되어 이를 라이너에 적용해보기로 했습니다.
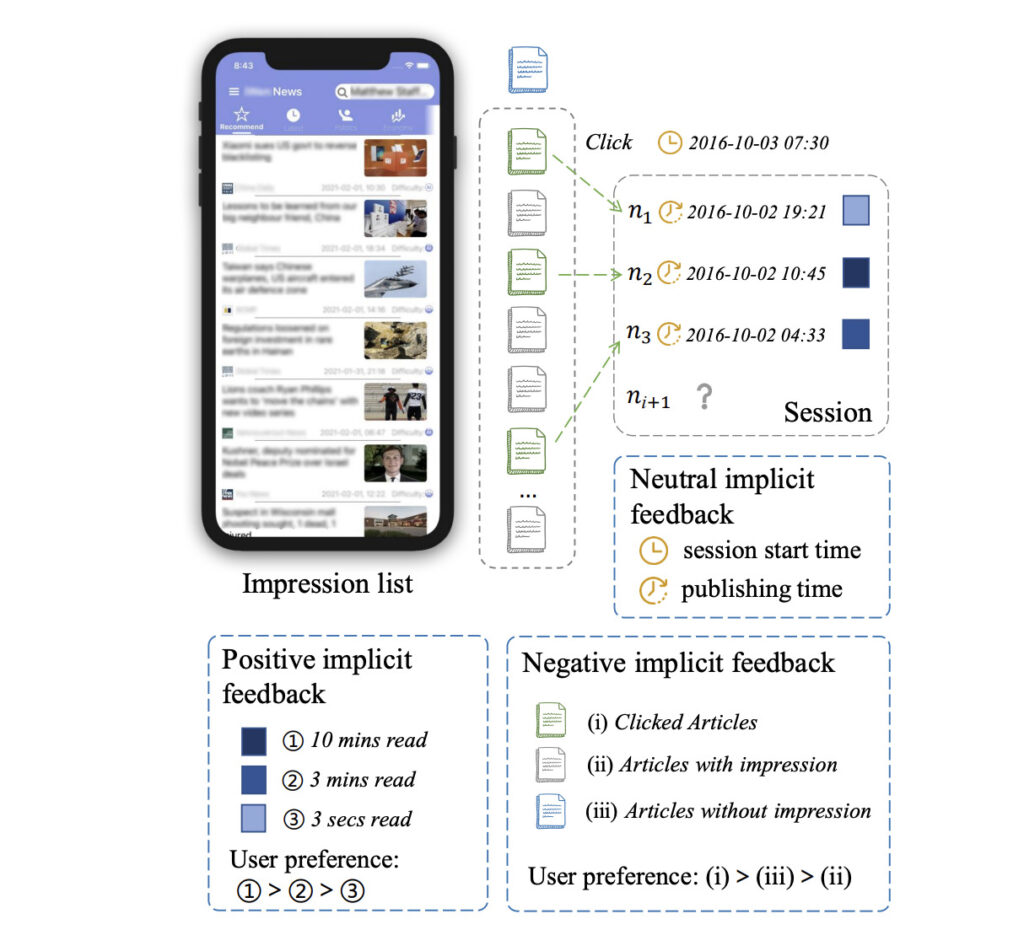
Session-based Recommender 구현 및 배포
먼저 논문에서 제시된 체류 시간, 세션 시작 시각 등을 포함하여 라이너 앱에서 수집할 수 있는 Implicit feedback들을 나열해보았습니다. 그리고 데이터 엔지니어인 팀(Tim)과 개편될 앱에서 각각의 피드백에 대한 로그를 어떻게 남기고 피쳐를 어떻게 가공할지에 대해 이야기를 나누었습니다.
대표적으로 체류 시간의 경우, 추천 피드에서 유저가 각 콘텐츠에 머무른 시간을 어떻게 측정할지가 주요 논의사항이었습니다. 유저가 오래 머문 콘텐츠일수록 유저의 관심사를 잘 대변하는 강한 Positive feedback으로 작용할 것이기 때문에 체류 시간을 잘 정의하는 것이 중요했습니다. 고민 끝에 저희는 추천 피드에서 발생한 로그를 2차적으로 가공해서 피쳐를 만들기로 했습니다. 앱에서 유저는 한 화면에 하나의 콘텐츠만을 볼 수 있어 서로 다른 두 콘텐츠의 노출 로그 사이의 Timestamp 간격을 계산하면 유저가 콘텐츠에 머무른 시간을 구할 수 있을 것이라 판단했고, 이를 체류 시간 피쳐로 두었습니다.
추가적으로 떠올렸던 Implicit feedback 중 하나는 유저의 콘텐츠 스크롤 비율입니다. Spotify의 논문 “Contextual and Sequential User Embeddings for Large-Scale Music Recommendation” (RecSys ‘20)에서 skip rate를 이용해 음악 트랙에 대한 유저의 만족도를 추정하는 데에서 힌트를 얻었는데요. 유저가 어떤 음악 트랙을 듣다가 마음에 들지 않으면 스킵 버튼을 누르는 것처럼, 라이너에서 어떤 콘텐츠를 클릭했다가 기대했던 내용과 다르면 유저가 스크롤을 내린 부분의 길이도 작을 수 있겠다는 생각이 들었습니다. 따라서 콘텐츠의 전체 길이 대비 유저가 최대로 스크롤한 부분의 비율을 계산해 콘텐츠 스크롤 비율 피쳐로 두었습니다.
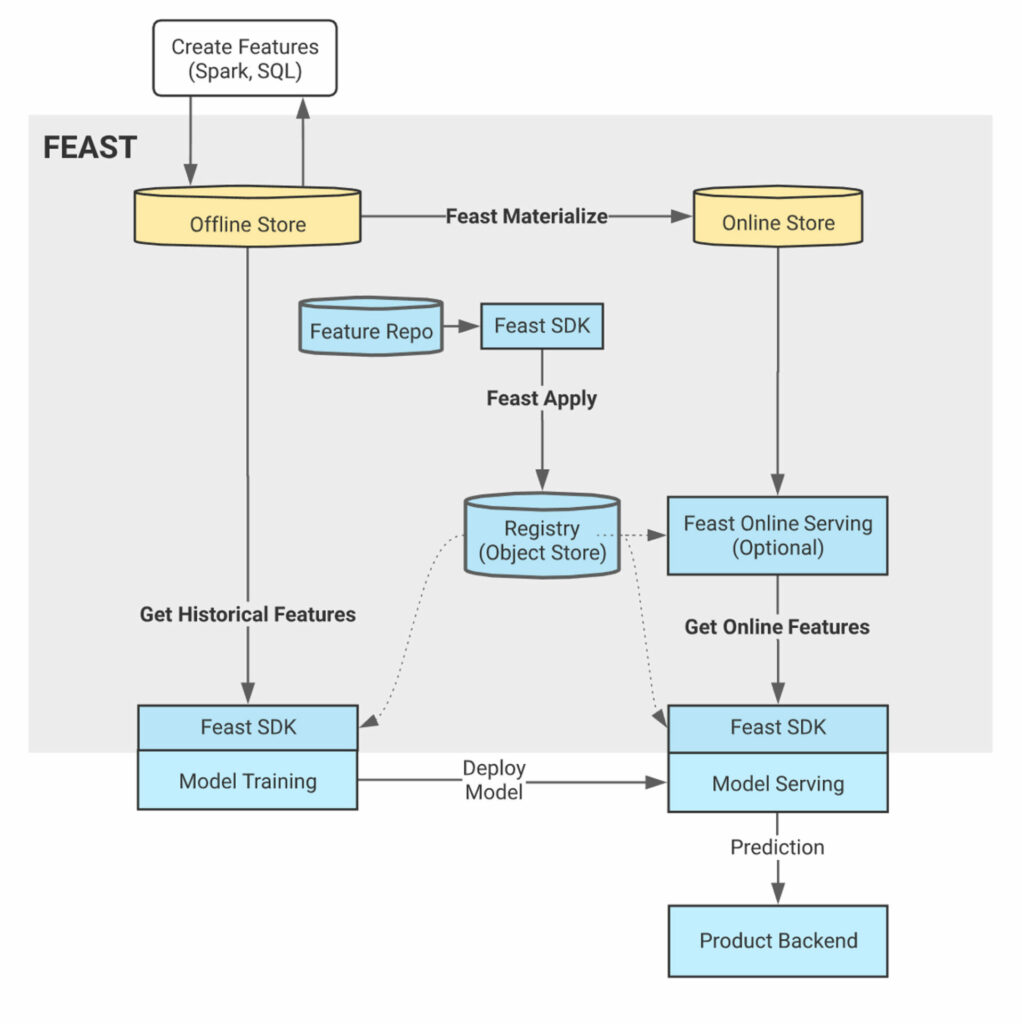
이렇게 구상한 피쳐들을 실시간으로 넘겨받기 위해 온라인 피쳐 스토어의 구축은 필수적이었습니다. 비록 모델 학습 시에서는 과거의 데이터를 잘 전처리하여 만든 오프라인 피쳐들을 이용할 수 있겠지만, 이를 프로덕트에 도입하기 위해서는 Inference 시에 온라인 피쳐를 받을 수 있어야 하기 때문입니다. 사실 유저의 피드백이 실시간으로 넘어오지 않는다면 세션 기반 추천 모델에서 해당 피쳐를 사용하는 의미가 없기도 합니다. 따라서 지난 분기 저희는 FEAST의 인터페이스를 참고하여 온라인 피쳐 스토어로 BigTable을 도입했습니다. 그 결과 스트리밍 파이프라인을 통해 실시간 로그를 정제하고 Inference 시에 필요한 피쳐들을 빠르게 넘겨받을 수 있게 되었습니다.
이와 동시에 저는 논문에서 제시된 모델 구조를 기반으로 세션 기반 추천 모델을 구현하여 오프라인에서 여러 실험을 진행했습니다. Evaluation 단계에서는 시퀀셜 추천 모델을 학습했을 때와 마찬가지로 faiss를 활용하여 실제 서빙 환경과 유사한 방식으로 Next item prediction 태스크를 잘 수행하는지를 평가했습니다. 이렇게 선정된 최종 모델은 베이스라인으로 둔 임베딩 평균 모델에 비해 약 160% 정도의 성능 향상이 있었습니다.
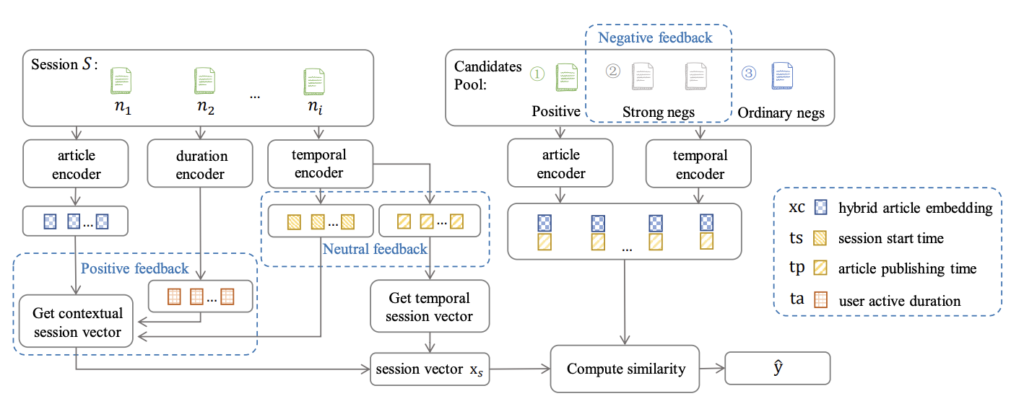
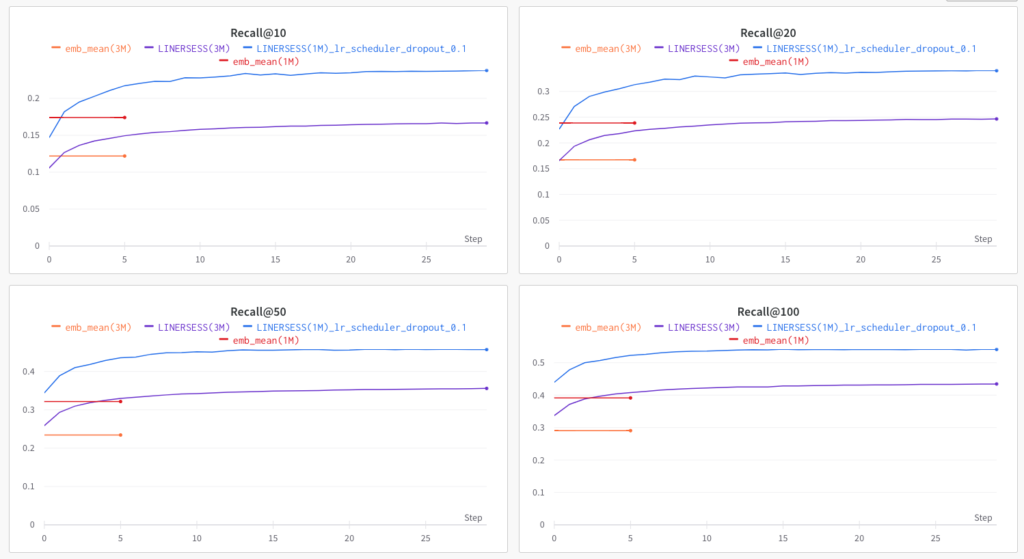
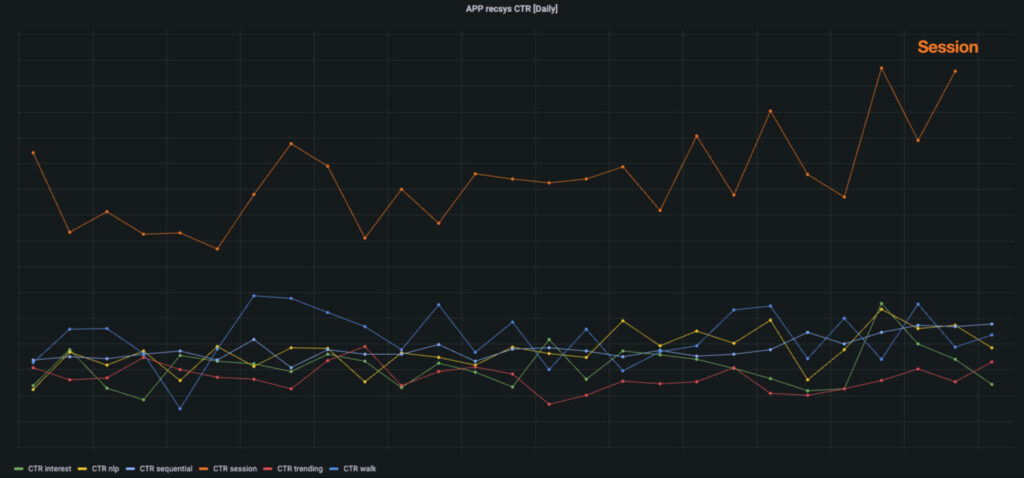
그렇게 지난 3월, 라이너 앱에 세션 기반 추천 모델을 성공적으로 배포했습니다. 이후 여러 정량적 지표를 트래킹하고 있는데, 기존 개인화 추천에 비해 세션 기반 추천의 CTR이 2~3배로 크게 오른 것을 확인할 수 있었습니다. 또 추천 피드를 정성적으로 살펴봤을 때에도 유저의 행동에 따라 추천 콘텐츠의 주제가 잘 모아지는 것을 확인할 수 있었습니다. 아래 영상을 보시면 처음에는 추천 피드에 정치, 개발 관련 콘텐츠가 나왔지만 프로덕트 관련 콘텐츠를 소비한 후에는 추천 피드에 프로덕트 관련 콘텐츠들이 많이 등장하는 것을 확인하실 수 있습니다.
마치며
지금까지 라이너 앱에 도입된 세션 기반 추천 모델에 대한 소개를 드렸습니다. 이제 라이너에서는 Implicit feedback을 실시간으로 반영한 콘텐츠 추천이 가능해져 유저들에게 더 많은 가치를 제공할 수 있게 되었습니다. 하지만 세션 기반 추천은 이제 겨우 첫 발을 내디뎠을 뿐 아직 발전의 여지는 많이 남아있습니다. 콘텐츠 노출 횟수에 따른 Impression discounting이나 최신성・다양성을 고려한 추천은 앞으로 해결되어야 할 중요한 과제입니다.
라이너는 더이상 하이라이팅 유틸리티가 아닙니다. 저희는 그동안 유저들이 직접 하이라이팅하고 스크랩 해왔던 데이터를 추천, 검색 기술과 결합하여 초개인화된 웹 플랫폼을 만들어나가고 있습니다. 그리고 이 과정에서 사람과 AI의 Co-Learning을 통해 정보 탐색과 정보 소비를 혁신시키려고 합니다.
저희 ML 플래닛은 어느덧 6명이 되었습니다. 하지만 저희가 풀고 싶은, 풀어야 하는 문제는 여전히 많습니다. 함께 문제를 해결하면서 성장하고자 하시는 분이 있다면 언제든지 연락주시면 감사하겠습니다. 앞으로도 라이너에 많은 관심과 응원 부탁드리며, 블로그를 통해 다음에 소개드릴 이야기들도 기대해주세요😀