PDF 코파일럿 개발기
LINER meets LLM
안녕하세요, 백엔드 엔지니어 그렉입니다. 오늘은 라이너가 LLM을 만난 이야기를 전해드리려고 합니다. Help People Get Smart Faster라는 미션에 맞춰 라이너 서비스 곳곳에 LLM이 들어가 기존에는 어려웠던 다양한 정보 처리 작업을 위임받고 있습니다. 그중에서 직접 개발에 참여한 PDF 코파일럿과 관련하여 이야기를 나눠보고자 합니다.
PDF 코파일럿은 사용자가 PDF의 내용을 더 빠르고 깊게 습득하기 위해 개발되었습니다. 사용자가 PDF를 하이라이트 하며 우측에 LLM을 대표하는 라이너 코파일럿과 대화를 나눌 수 있도록 채팅창이 제공됩니다. 답변이 끝난 뒤에는 다음에 하면 좋을 질문을 같이 알려주고 클릭으로 계속해서 중요한 대화를 이어갈 수 있게 합니다.
LLM(Large Language Model)은 쉽게 말하면 인풋/아웃풋이 자연어인 추론 기계입니다. 많이 들어보셨을 ChatGPT가 LLM의 일종입니다. 언어 모델에 텍스트를 넣어주면 뒤이어 나올 내용을 통계적 연관성을 기반으로 생성해 줍니다. 모델이 거대해지고 데이터가 늘어나며 이 통계적 연관성이 우리가 지능이라고 말할 수준까지 올라왔고 LLM의 시대가 열렸습니다.
기존에 어려웠던 정보 처리 작업, 요약, 추론 등이 가능해지며 사람이 정보를 소화하기 위해 해야 할 많은 부분이 LLM에 위임될 것으로 보입니다. 라이너에는 다양한 텍스트 데이터가 사람의 선택을 받아 저장되어 있었고, 사용자의 대부분도 정보를 모으고 처리하는 것에 관심이 많았기에 LLM은 라이너에 날개가 되어줄 수 있겠다고 직관적으로 알 수 있었습니다.
PDF Copilot Architecture
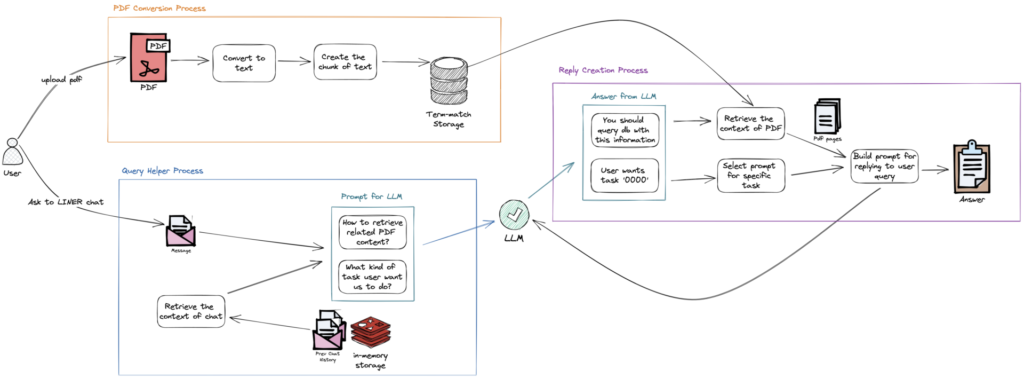
라이너에서 구현한 PDF 코파일럿은 3가지 파트로 구성되어있습니다. PDF 변환부, 질의해석부, 답변생성부가 각각 순차적으로 진행되며 사용자의 질문을 받게 됩니다.
PDF Conversion Part
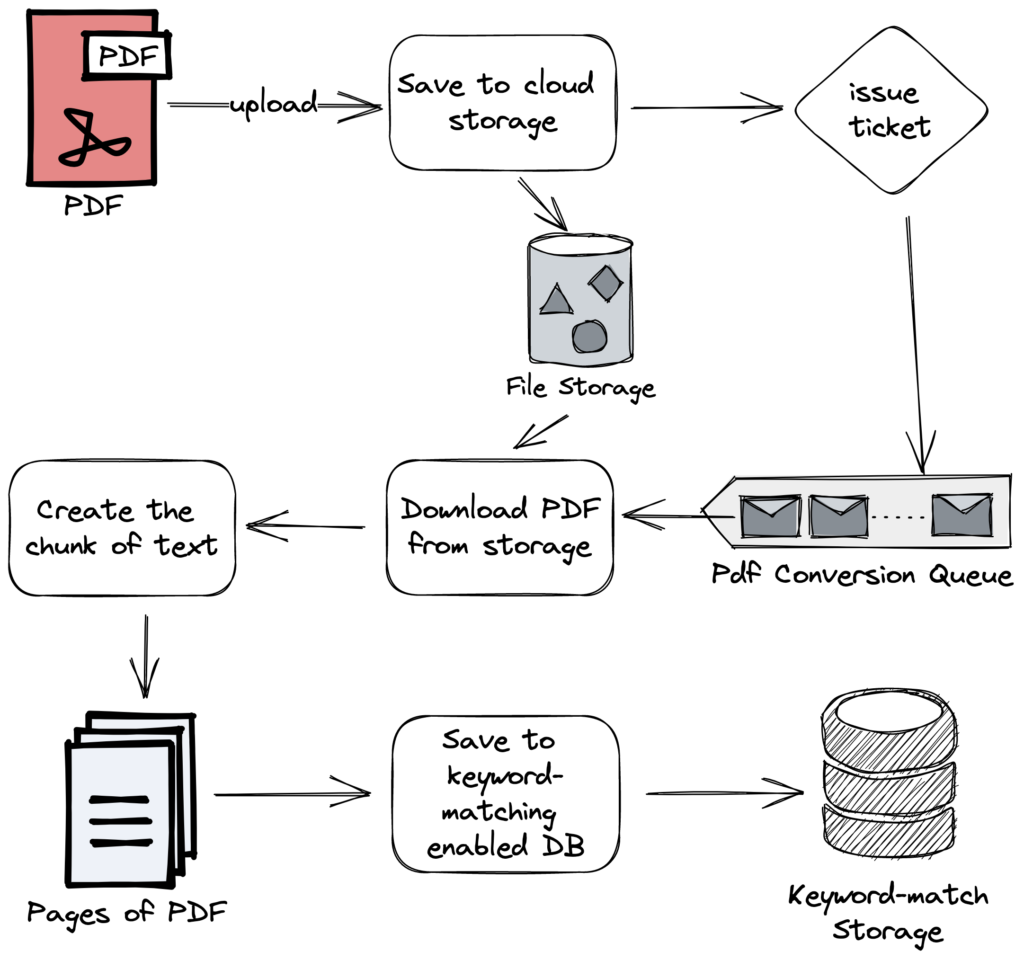
첫 번째 PDF 변환부는 LLM에게 넘겨줄 텍스트 정보를 가공하는 단계입니다. 사용자가 라이너 서비스를 통해 PDF 파일을 클라우드 스토리지에 올리면, 변환 서비스에 전달될 티켓이 큐에 들어갑니다. 변환 서비스는 큐 메시지를 받아서 저장된 PDF를 내려받고 텍스트로 변환한 뒤에 페이지 단위로 자르게 됩니다. 페이지 단위의 PDF 텍스트는 키워드 매칭으로 검색할 수 있는 문서 DB에 저장되게 됩니다. 이후 사용자의 질의에 대답하기 위해 이 문서 DB를 활용하여 키워드 쿼리를 실행하게 됩니다.
Query Helper Part
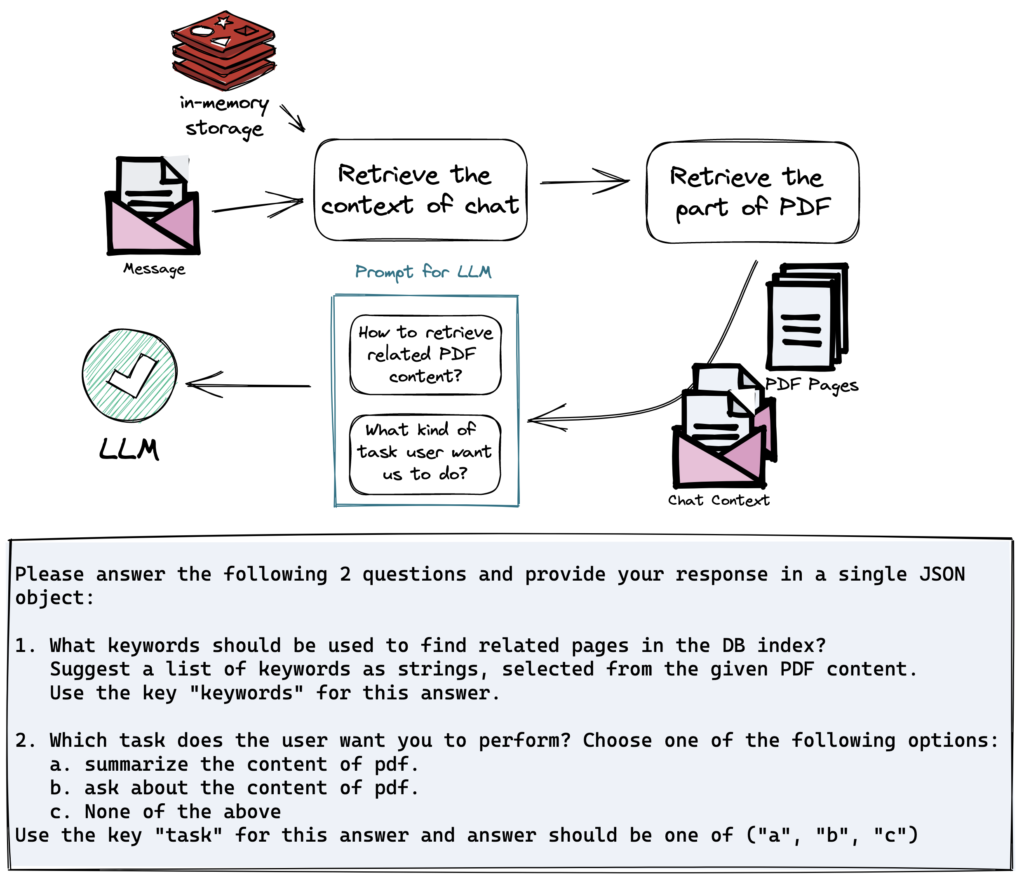
두 번째 쿼리해석부는 사용자의 질의문을 분석해서 최종 답변을 생성하기 위한 데이터를 가공하는 단계입니다. 제일 먼저 사용자의 채팅 맥락을 가져오기 위해 인메모리 DB에 저장된 채팅 기록을 불러옵니다. 그리고 사용자가 질의하는 PDF에 대한 정보를 주기 위해 PDF의 앞부분 내용을 가져옵니다. 어떤 대화를 나누었고(채팅 맥락), 어떤 PDF에 대한 질문인지(PDF 맥락) LLM에 알려주며 2가지를 질문합니다.
- 질문과 관련된 PDF를 어떻게 가져올 수 있을까? -> (어떤 키워드로 쿼리를 날릴까?)
- 사용자의 질문이 어떤 의도를 가지고 있을까? -> (요약, 질문, 기타 등등 중에 골라줘)
그리고 이 두 질문에 대한 답변은 최종 단계에서 쓰이게 됩니다.
Reply Creation Part
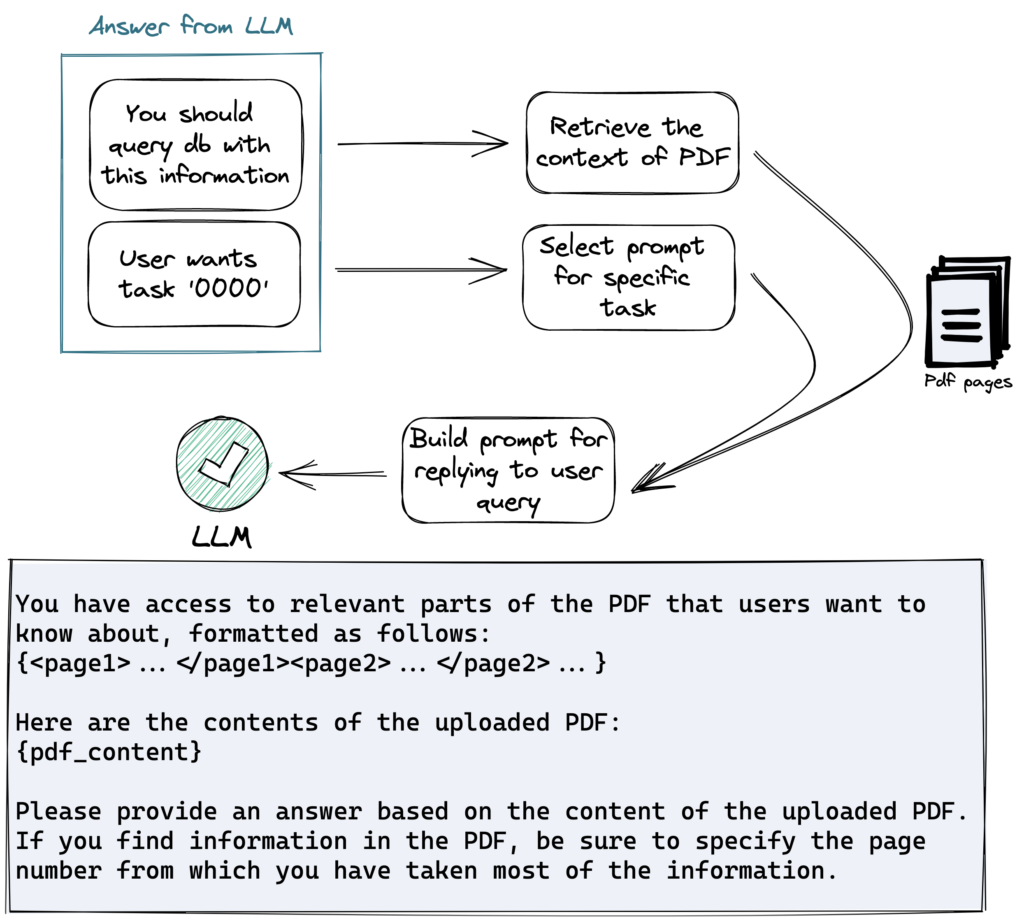
이전 단계에서 제공된 답변으로 이번에는 진짜 연관된 PDF 내용을 조회합니다. 그리고 태스크별로 미리 준비된 프롬프트를 가져옵니다. 이 두 가지 정보를 섞어서 최종적으로 답변을 생성합니다.
고민했던 것들
프롬프트 사이즈 제한
GPT의 프롬프트 토큰 사이즈 제한 때문에 일정 크기 이상의 PDF는 모든 내용을 넣어줄 수 없습니다. 만약 사이즈 제한이 없다면 이 문제가 해결될까요? 그렇게 된다고 하더라도 인풋 소스를 처리하는 것이 모두 비용이기 때문에 엔지니어링 관점에서는 비효율이 발생합니다. 이러나저러나 필요한 정보가 최대한 압축된 프롬프트를 만드는 것이 엔지니어링 적으로도, 실제 제약을 고려하더라도 맞는 방향이라고 생각했습니다.
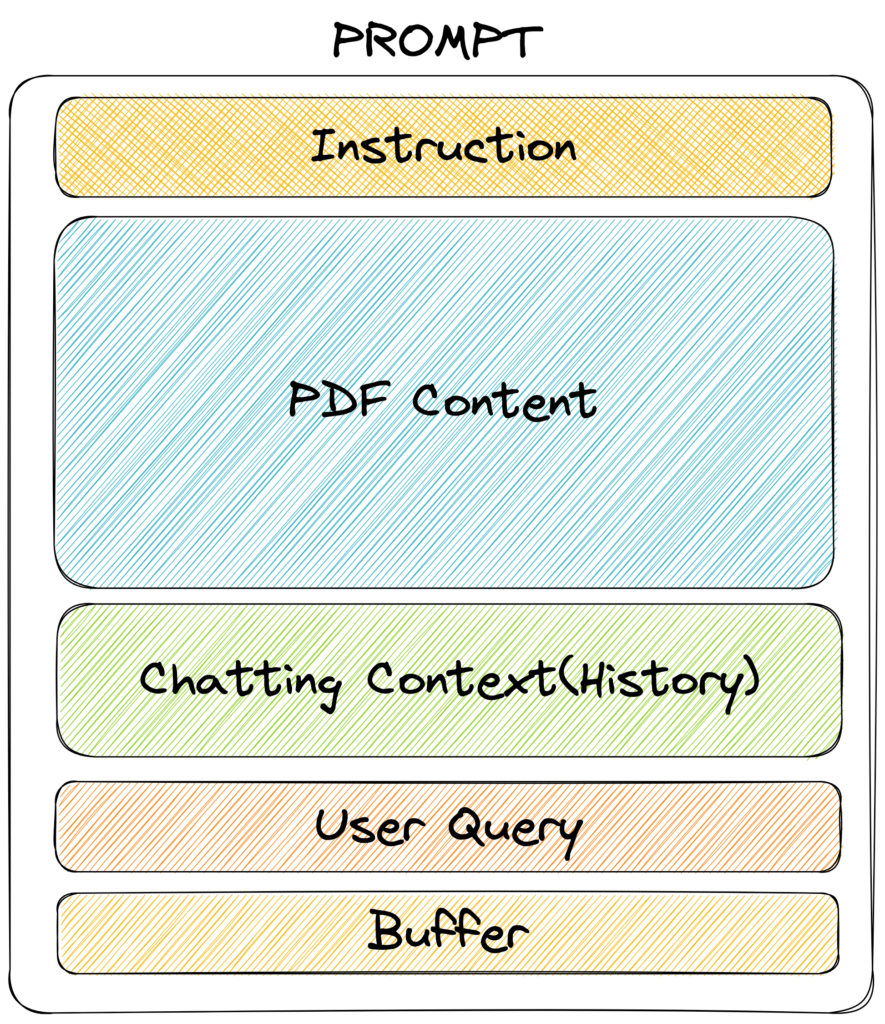
프롬프트를 구성하는 것은 마치 맛집 대표 메뉴의 레시피를 만드는 것과 유사했습니다. 어떤 내용이 어떠한 비중으로 들어가야 할지, 어떻게 연관 내용들을 구성해야 할지 계속해서 실험하며 Ad-HOC 하게 수정해야 했습니다. PDF에 대해 LLM이 최대한 많이 알고 있으면 좋으니, 프롬프트에서 PDF 텍스트가 최대한 많이 들어가도록 구성했습니다. Instruction은 최대한 간단히 하려고 했고 사용자의 질의문 크기가 유동적이기 때문에 버퍼를 두었습니다. 채팅 맥락을 유지하며 대화해야 몰입을 줄 수 있다고 생각하여 해당 부분도 포함했습니다.
아웃풋 포맷 신뢰성
앞서 말씀드렸던 프롬프트는 2가지 질문을 LLM에 하게 되는데, 각 질문에 대한 답변을 해석할 수 있도록 약속된 포맷으로 답변이 되어야 합니다. JSON으로 답변받고 싶었고 각 태스트에 대한 대답을 연관시켜서 JSON object로 내려달라고 했었습니다. 대부분의 경우는 문제가 없었지만, 가끔 LLM이 답변 앞에 혹은 끝에 답변 생성에 대해 부연 설명을 했습니다. 이 경우 단순히 JSON으로 디코딩하려고 하면 에러가 났고 답변 후처리 및 프롬프트 수정이 필요했습니다.

여러 태스크를 하나의 요청에 담는 것이 문제이기 때문에, 각각의 태스크에 대한 답변을 바로 사용할 수 있는 형태로 로직을 변경해도 됩니다. 그렇지만 이 경우 API 호출이 늘어납니다. 결국 엔지니어는 답변의 신뢰성과 API 호출 수에 대한 트레이드 오프를 문제를 마주하게 됩니다. PDF의 코파일럿의 경우는 API 비용이 더 중요했기 때문에 어느 정도의 신뢰성이 보장된다고 느낀 뒤에는 후처리 로직에 힘을 쓰는 형식으로 이를 해결했습니다. 개발하시는 기능의 요구사항에 따라 적당히 조정하면 된다고 생각합니다.
Future work
PDF 코파일럿을 더 똑똑하게 만들 방법은 아직 많이 남아있습니다. 실제로 개발을 진행하며 앞으로 더 손보면 좋을 것들을 짚어보려 합니다.
더 정확한 PDF 정보를 가져오자
현재는 키워드 매칭으로 페이지 단위의 PDF를 가져오고 있습니다. 하지만 LLM이 적절한 키워드를 뽑아주지 않는다면, 무관한 내용을 가져올 수도 있습니다. 이 이슈를 해결하기 위해 잘린 텍스트 조각에 대한 벡터를 계산하고 저장하여 활용하는 방법이 있습니다. 사용자 질의를 같은 차원의 벡터로 변환하여 유관한 내용을 검색하는 방식입니다. 벡터 검색의 경우 LLM에게 쿼리에 쓸 키워드를 물어보지 않아도 되기 때문에 더 효율적으로 로직을 개선할 수 있습니다.
다만 사용자가 정확히 키워드를 포함하여 질문하는 경우, 키워드 매칭 검색도 유효하기 때문에 이 두 가지를 적절히 섞어 후보 텍스트 덩어리를 가져오는 것이 제일 좋은 방법이라고 생각합니다. 그렇다면 각 검색 방법이 어떤 비율로 조정되어야 하는지, 두 쿼리를 어떻게 프로덕션 서비스에서 요구하는 퍼포먼스에 맞게 실행시킬 수 있는지는 노하우의 영역이 될 것으로 보입니다.
마지막으로 페이지 단위가 아닌 더 작은 단위로 텍스트를 자르고 유관한 정보들을 더 날카롭게 가져올 수 있다면, 더 다양한 범위의 PDF 내용이 포함될 수 있습니다.
나를 잘 아는 라이너 코파일럿
라이너에는 사용자가 하이라이트한 내용들이 모입니다. 만약 라이너 코파일럿이 사용자가 이전에 했던 하이라이트를 참고하여 사용자의 성향을 파악한다면 관심 있을 만한 내용을 더 부각하거나 이미 알고 있는 내용은 제외하는 등 사용자의 입맛에 맞는 답변을 해줄 가능성이 커집니다. 더 나아가 PDF의 난이도와 사용자의 지식수준까지 파악할 수 있다면 라이너 코파일럿은 더 빠르게 흡수할 수 있는 형태로 정보를 가공하여 사용자에게 제공할 수 있습니다. 다만 이 경우 프롬프트에 추가적인 정보가 들어가야 하므로, 제한된 입력 사이즈를 어떻게 구성해야 할지 다시 고민해야 하겠지만요.
엔지니어링 퍼포먼스
앞서 말씀드린 것처럼 벡터 검색을 섞어서 쓰는 경우, 키워드 매칭에만 의존하지 않아도 되기 때문에 GPT API 호출을 하나 줄일 수 있다고 말씀드렸습니다. PDF 코파일럿에서 가장 오래 걸리는 작업은 GPT API 호출이기 때문에 실제로 호출 하나가 줄어들면 사용자 경험은 훨씬 더 좋아집니다. 이외에 엔지니어링적으로 퍼포먼스를 올려줄 수 있는 기회는 실제로 벡터 스토리지의 퍼포먼스 이슈, GPT API 호출이 도중에 끊겨서 다시 요청해야 하는 경우 등 다양하게 존재합니다. 코드를 통해 최소의 비용으로 최대의 효용을 내는 일이 결국 소프트웨어 엔지니어의 일이라고 생각하기에, 계속해서 여러 이슈들을 해결하며 더 좋은 프로덕트를 만들어야 한다고 생각합니다.
마치며
말로만 들었던 LLM을 실제로 프로덕트에 넣어보며 기존에는 가능하지 않았던 작업이 가능해지는 것을 느꼈습니다. 앞으로 굉장히 다양한 태스크들이 LLM을 통해 가능해지리라는 것을 전혀 의심하지 않습니다. 이미 Github Copilot을 통해 개발자의 생산성을 높여주고 있고, 프로덕트에 직접 들어가며 사용자들의 생산성까지 높여주고 있으니, 이제 23년도 이후의 지식 노동자들은 LLM을 파워포인트나 워드처럼 써야 할지도 모르겠습니다. 그리고 백엔드 엔지니어로서도 LLM이 시스템 내 들어와서 중요한 역할을 빠르게 할 수 있도록 인프라적인 준비도 해야 한다는 것을 알 수 있었습니다.
LangChain, Llama-index와 같은 LLM 에코시스템들을 잘 익혀 사용자의 숨은 니즈를 잡아내는 멋진 스타트업이 될 수 있도록 노력해야겠다는 생각도 들었습니다.
고로 이 글을 읽게 되시는 개발자분들, 얼른 LLM하세요!