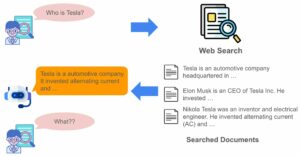
그 많던 벡터는 다 어디로 갔을까? Milvus 활용기
우리가 마주한 문제
안녕하세요, 머신러닝 엔지니어 카터입니다. 지난 콘텐츠 기반 필터링 구축기 포스트를 통해 텍스트 임베딩을 활용해 구현한 추천 엔진에 대한 소개를 드린 적이 있습니다. Huggingface + TorchServe + ScaNN 등의 기술 스택으로 구성“되었던” 해당 엔진은 아직까지 Candidate Generator의 역할을 톡톡히 수행해주고 있는 알짜 엔진입니다.
그러나 서비스를 운영하다 보면 항상 현 시스템의 페인 포인트를 마주하게 되곤 합니다. 해당 엔진 역시 예외는 아니었는데요. 기존 콘텐츠 기반 필터링 엔진의 경우 두 가지 큰 페인 포인트를 제게 안겨주었습니다. 첫 번째는 추천 후보군이 될 문서를 엔진에 새로이 추가하는 과정이 수월하지 않다는 점입니다. 이게 어떤 의미인지 코드를 통해 한 번 살펴보겠습니다.
normalized_dataset = dataset / np.linalg.norm(dataset, axis=1)[:, np.newaxis]
searcher = scann.scann_ops_pybind.builder(
normalized_dataset,
10,
"dot_product",
).tree(
num_leaves=2000,
num_leaves_to_search=100,
training_sample_size=250000,
).score_ah(
2,
anisotropic_quantization_threshold=0.2,
).reorder(100).build()위 코드는 ScaNN의 예제 코드 중 일부입니다. 코드를 보시면 normalized_dataset 이라는 매트릭스 객체를 ScaNN Builder의 인자로 제공하는 방식으로 학습이 진행됩니다. 한 번 인덱스가 구워진 후, 새로운 후보군 아이템을 추가하는 방법은 별도로 존재하지 않습니다. 즉 새로이 추가하고자 하는 아이템이 포함된 매트릭스를 만든 후, 해당 매트릭스로 인덱스를 재빌드하는 방법 밖에 없는 것이죠.
{
0: "ae33d7db-0cb7-3ea2-90b9-d54b05feb743",
1: "5dd74378-241c-3305-a4bd-0c2f1ac4b501",
...
}불편한 점은 이것만이 아닙니다. normalized_dataset 매트릭스의 각 행에 해당하는 벡터가 어떤 아이템의 벡터인지 정보를 별도로 기록해두어야 하는 점 역시 시스템 운영을 복잡하게 만드는 요소였습니다. 위와 같이 행 번호에 따른 문서 아이디 정보를 쌍으로 저장한 후, 게이트웨이 서버의 메모리 혹은 Redis 등의 외부 메모리에 올려 문서 아이디를 변환해 사용자에게 반환해주어야 하는 아주 불편한 구조였습니다.
두 번째 페인 포인트는 이 글의 제목과도 관련이 있는 것으로, 아이템 벡터를 Pre-compute 해둔 후 저장을 한다 했을 때 바람직한 구조는 과연 무엇인가에 대한 고민에서 발생했습니다. 프로덕션 레벨의 추천 시스템 구조를 살펴 보게 되면 대부분 오프라인 배치 추론을 통해 특정 사용자에 대한 추천 결과를 미리 구워둔 후, 해당 결과 값을 반환해주는 방식으로 요청에 대한 처리가 진행되게 됩니다.
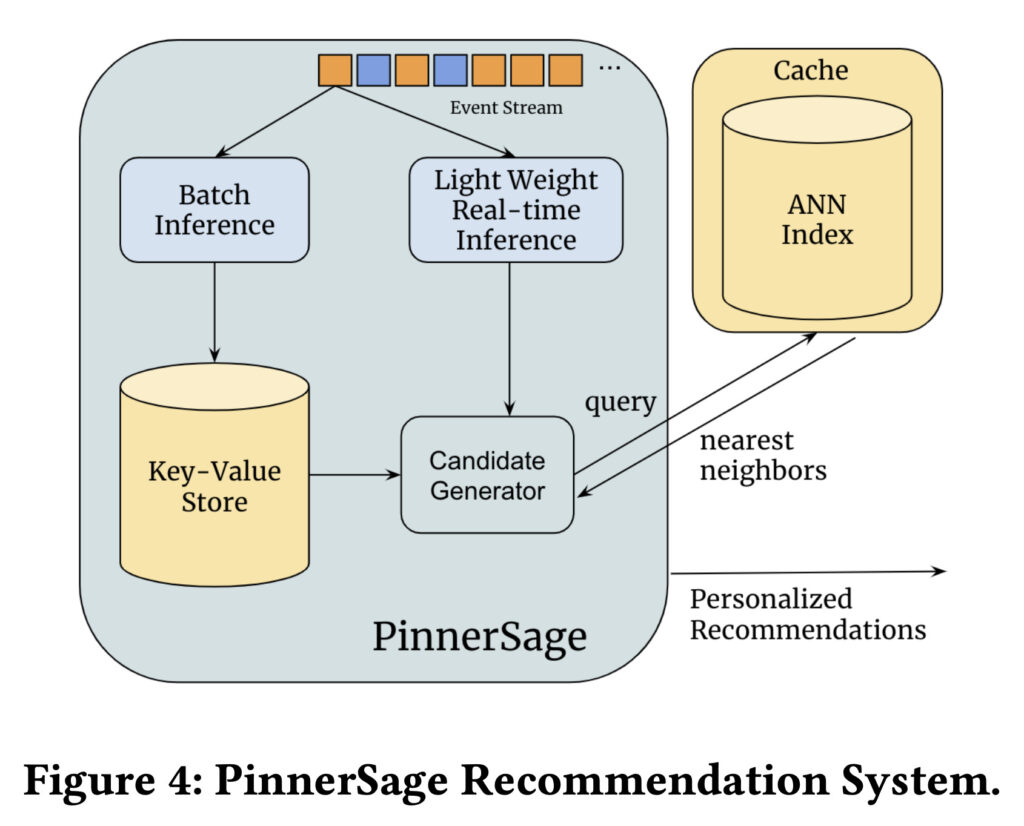
이같은 구조를 디자인하는 과정에는 Key-Value 스토어에 대한 고민 뿐만 아니라 사용자 및 아이템에 대한 벡터 저장소에 대한 고민도 필연적으로 발생하게 됩니다. 즉, 수백만 개의 x 수백 차원의 벡터를 고가용성으로 저장해 관리할 수 있는 저장소에 대한 고민을 하게 된 것입니다.
이에 대한 리서치를 많이 진행했음에도 이같은 “벡터 저장소” 구축에 대한 레퍼런스를 찾기란 여간 어려운 일이 아닐 수 없었습니다. MongoDB, Elasticsearch와 같은 Document Database를 고민해보기도 하고, GCP의 유즈 케이스를 참조해 BigTable을 고민해보기도 했지만 저희가 겪은 여러 페인 포인트를 한 번에 해결할 수 있는 솔루션을 찾을 수 없었습니다.
왜 Milvus인가?

재밌게도 처음으로 팀 내 Milvus에 대한 논의가 이루어지게 된건 위 페인 포인트에 대한 해결책으로가 아니었습니다. 현재 라이너는 어플리케이션을 통해 개인화 추천 뿐만 아니라 검색 기능도 사용자에게 제공을 하고 있는데, 검색 기능에 시맨틱 스코어(e.g. Semantic Textual Similairty)를 녹일 수 있는 안을 고민하던 중 Milvus에 대한 논의를 시작하게 되었습니다.
Milvus는 2019년 Similarity Search Engine 오픈 소스로 시작된 프로젝트입니다. 현재는 리눅스 재단의 AI & Data (이하 LF AI & Data) 산하의 프로젝트로 채택되어 활발히 개발되고 있는 오픈 소스 프로젝트이기도 합니다. LF AI & Data를 통해 관리되고 있는 대표적인 프로젝트로는 ONNX, KServe, Horovod, Feast 등이 있습니다.

리눅스 재단의 지원을 받아 개발되고 있는 것뿐만 아니라 Milvus는 트래픽이 많이 발생하는 여러 세계적인 테크 기업 (e.g. Ebay, Tencent, Baidu, …) 에서도 활용되고 있는 바, 어느 정도 안정성과 레퍼런스가 쌓인 프로젝트라는 내부적 판단을 내릴 수 있었습니다.
또한 (눈치채신 분도 계시겠지만) Similarity Search Engine 으로 시작된 프로젝트이기에 Milvus는 Approximate Nearest Neighbor Search 를 위한 알고리즘, 인덱싱 뿐만 아니라 안정적으로 벡터를 저장해 꺼내어 쓸 수 있는 Vector Database의 기능을 모두 제공하는 툴이기도 합니다. 앞서 언급된 기존 시스템의 페인 포인트를 모두 해결해줄 수 있는 솔루션인 셈이죠!
염원하던 하나의 솔루션을 찾게 된 후, 데이터 엔지니어 동료 Tim이 Milvus 도입과 관련해 프로젝트 안정성과 직접 운영 가능 여부 등에 대해 최종적으로 진단을 해주었습니다. 그렇게 현재 라이너 추천 시스템에 Milvus를 도입하기 적합하다는 결론에 도달하게 되었고, Milvus를 시스템에 이식하게 되었습니다. Milvus 도입과 구축에 대한 자세한 이야기는 차후 Tim이 블로그를 통해 공유해주실 예정입니다 (Tim이 빠른 시일 내에 글을 작성할 수 있도록 많은 관심 부탁드립니다 🙏).
Milvus 도입을 통해 달라진 시스템
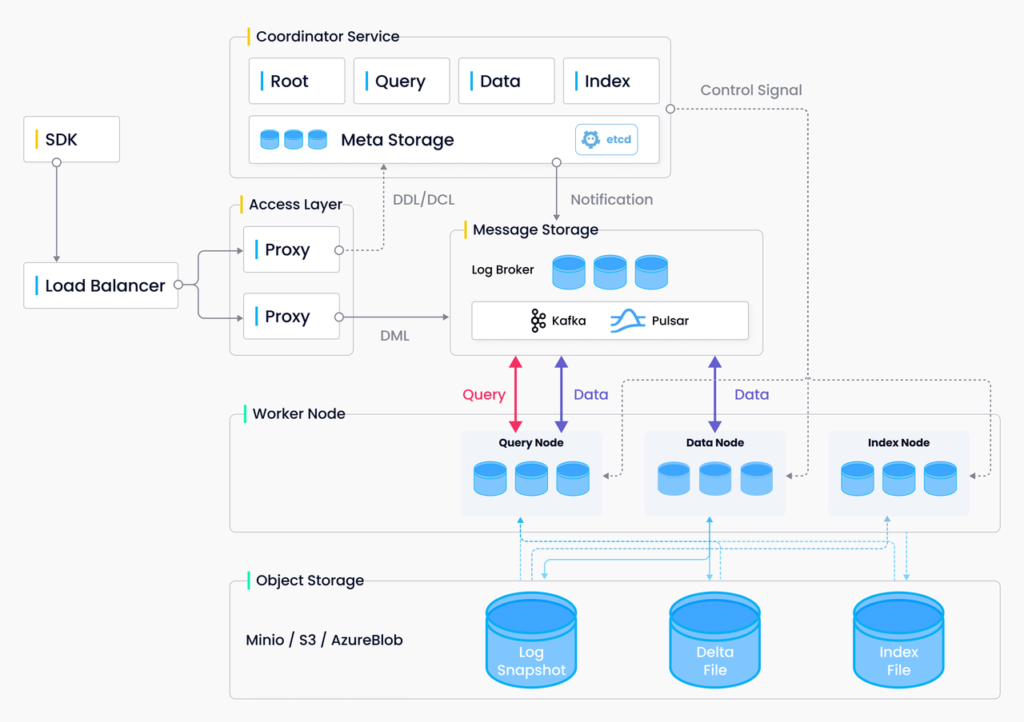
이제 Milvus를 라이너 추천 시스템에 도입하게 되며 달라진 점들에 대한 소개드리겠습니다. Milvus는 위 그림과 같은 구조로 클러스터가 구성됩니다. 시스템에서 사용하는 언어와 호환되는 SDK를 통해 데이터를 적재하거나, 데이터를 반환해올 수 있는데요. 이때 Query, Index 등 서로 다른 노드들이 독립적인 역할을 수행하게 됩니다. 새로운 데이터의 추가, 인덱스 구성은 Index Node가 Boolean Search 와 Vector Search 는 Query Node가 작업을 담당하게 됩니다.
앞서 도입부에서도 언급드렸듯 저희는 라이너에 새로이 적재된 문서도 곧바로 추천의 대상이 될 수 있도록 하는 파이프를 구축하고자 했습니다. 그러기 위해서는 인덱스가 이미 구축되어 있을 때에도 새로운 노드의 추가가 가능해야 하는 구조가 필요한데요. Milvus는 이러한 요구사항을 세그먼트(Segment)의 개념으로 해결하고 있습니다.
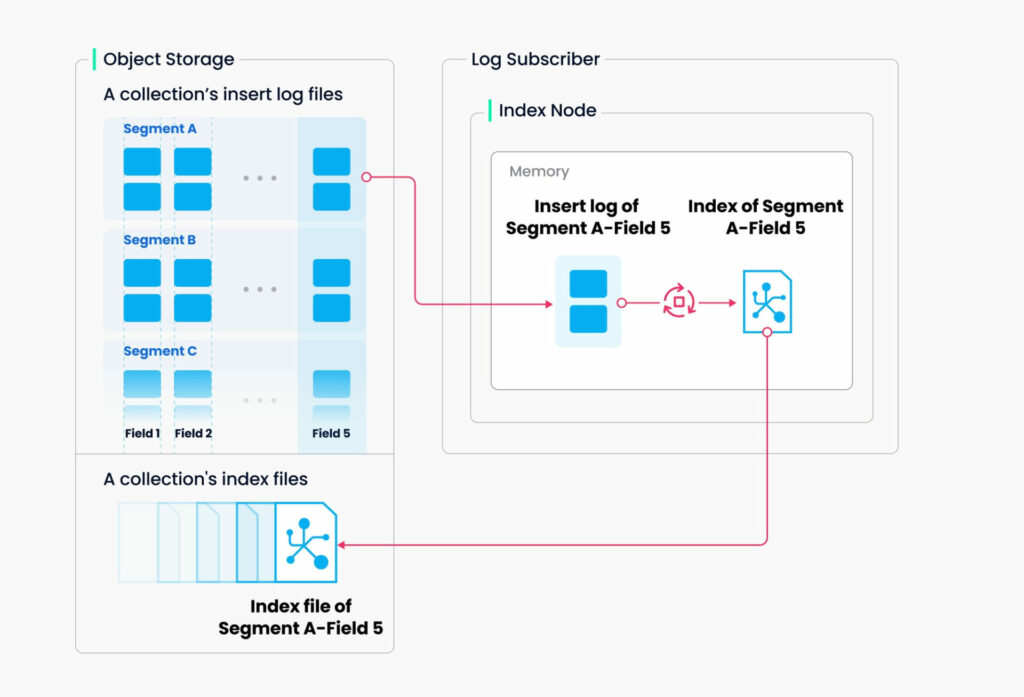
To avoid frequent index building for data updates, a collection in Milvus is divided further into segments, each with its own index.
인덱스 노드 아키텍처와 Milvus의 철학에 따라 Milvus에서 발생하는 데이터 추가와 쿼리 작업은 모두 세그먼트 단위로 이루어지게 됩니다. 따라서 새로운 아이템을 추가하고자 했을 때 기존 세그먼트에 공간이 남은 경우 기존 세그먼트에, 기존 세그먼트에 공간이 없는 경우 새로운 세그먼트가 생성되어 아이템이 추가되게 됩니다. 즉, 아이템 추가를 위해 매번 새로이 인덱스를 빌드할 필요가 없어지게 되는 것이죠. 세그먼트와 관련한 보다 자세한 개념은 공식 문서를 참고하시면 됩니다.
Milvus 도입을 통해 최초로 Milvus 콜렉션에 인덱스를 빌드한 후 발생한 아이템에 대해서는 아이템 벡터를 해당 콜렉션 내 세그먼트에 추가하는 방식으로 추가가 가능해졌습니다. 매일 새로운 문서를 콜렉션에 추가해주는 작업은 Airflow에 DAG를 등록해 처리할 수 있도록 배치 파이프를 구성했습니다.
다음으로 기존 ScaNN 활용안에서는 매트릭스의 행 번호에 해당하는 문서 아이디를 기록해두었다가 변환하는 작업이 필요했습니다. 아래 코드와 같이 말이죠.
func RetrieveDocumentsScann(embedding []float32) []db.EsDocument {
predictions := db.ScannSearch(embedding)
var esIds []string
for _, pred := range predictions {
esIds = append(esIds, utils.IdxToId[strconv.Itoa(pred.Index)])
}
documents := db.GetEsDocuments(esIds)
return documents
}하지만 이제는 Milvus 콜렉션에 벡터에 대한 메타 정보를 함께 레코드 개념으로 기록해둘 수 있기 때문에 이같은 불필요한 변환 과정을 거치지 않아도 문서 아이디를 바로 반환 받아 활용할 수 있게 되었습니다. 이로 인해 코드가 간결해졌을 뿐만 아니라 행 번호에 따른 문서 아이디를 저장해 관리하고 업데이트 하는 등의 비용 절감까지 이어져 저희에게 아주 큰 이득을 가져다 주었습니다.
func RetrieveDocumentsMilvus(embedding []float32) []db.EsDocument {
esIds := db.MilvusSearch(embedding)
documents := db.GetEsDocuments(esIds)
return documents
}마지막으로 이제는 아이템을 실시간으로 벡터로 변환해야 하는 작업이 있다면, 바로 변환하기 보다 Milvus에 해당 아이템에 대해 이미 등록된 벡터가 있는지 검색해 재사용하는 방식으로 구조를 변경해 Vector Database로서의 역할까지 기대할 수 있게 되었습니다. 해당 구조를 통해 오프라인으로 아이템 벡터를 미리 구워둔 후, 서빙 시 재사용 할 수 있게해 레이턴시를 크게 개선할 수 있었습니다. 이 정도면 저희가 겪은 문제에 한해서는 Silver Bullet 역할을 해주었다고 할 수 있겠네요.
milvusEmbeddings := db.MilvusQuery(documentIds, common.MilvusQueryCollection)
for i, document := range documents {
...
go func() {
defer wg.Done()
if val, ok := milvusEmbeddings[documentIds[i]]; ok {
totalEmbeddings[i] = val
return
}
...
}
}
마치며..
Milvus 도입을 통해 기존 시스템이 가지고 있던 많은 문제를 해결할 수 있게 되었고, 시스템 복잡도도 함께 낮출 수 있게 되었지만 이 과정이 순탄했던 것만은 아닙니다. Milvus를 안정적으로 운영한 사례에 대한 레퍼런스를 찾아볼 수 없었기에 클러스터 운영에 있어 여러 고충을 겪기도 했고, 아직까지는 불친절한 문서로 인해 시간을 헛되이 쓰게 되는 일도 많았습니다.
그러나 이 과정을 통해 더 나은 머신러닝 시스템 디자인을 위해 어떤 점을 고려해야 하는지, 우리가 겪고 있는 페인 포인트에 대한 백로그 관리는 어떻게 하는게 좋은지, 새로운 솔루션은 언제 & 어떻게 이식하는게 좋은지에 대한 고민을 팀 내부에서 해볼 수 있었기에 소중한 경험을 했던 과정이라 이야기 할 수 있을 것 같습니다.
라이너 머신러닝 조직은 적은 인원이 빠르게 변하고 생겨나는 요구사항에 대응하기 위해 골똘히 고민하고, 긴밀히 논의하며 빠른 성장을 이루어 나가고 있습니다. 라이너에서 다양하고 재밌는 문제를 풀며 함께 고공 성장하실 분들을 기다리고 있습니다. 많은 관심 부탁드리며, 다음에 블로그를 통해 소개드릴 이야기들도 기대해주세요!