Human-AI Co-Learning을 향해! 강화학습 기반 랭킹 모델 도입기
안녕하세요. 머신러닝 엔지니어 에디입니다😀
오늘은 최근 라이너의 콘텐츠 추천 시스템에 도입된 강화학습 기반의 랭킹 모델에 대한 소개를 드리려고 합니다.
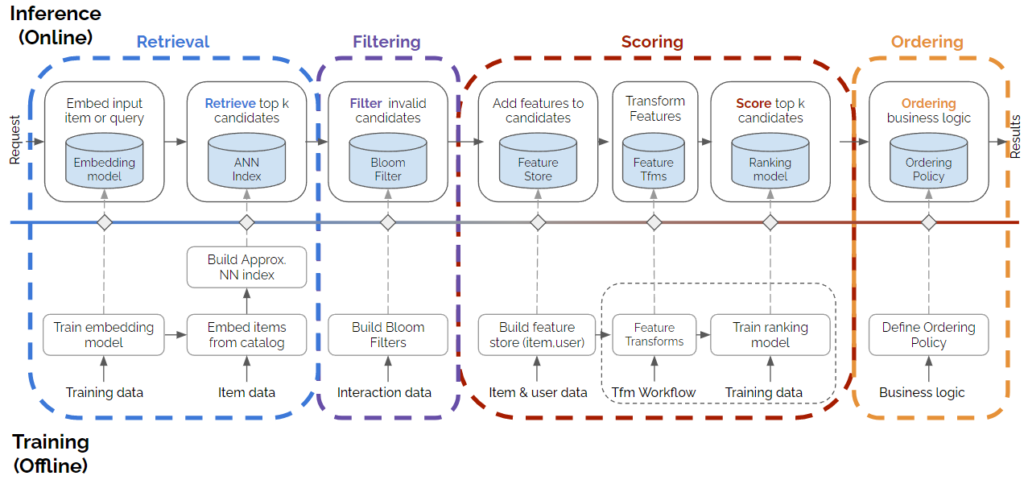
라이너의 추천 시스템은 위 그림과 같은 Multi-Stage 구조를 이루고 있습니다. Retrieval 단계에서 여러 모델이 저마다의 방식으로 추천 콘텐츠 후보군을 모아오면, Filtering 단계에서는 Bloom Filter가 불필요한 콘텐츠를 제거합니다. 이후 Scoring 단계에서 필터링된 콘텐츠의 나열 순서를 정해주는데요. 기존에 라이너에서는 Reciprocal Ranking Fusion 방식을 이용하여 콘텐츠에 랭킹을 매겨주고 있었습니다. 즉, 각 Retrieval 모델이 도출한 콘텐츠의 순위를 가중합하여 랭킹 스코어로 활용했습니다.
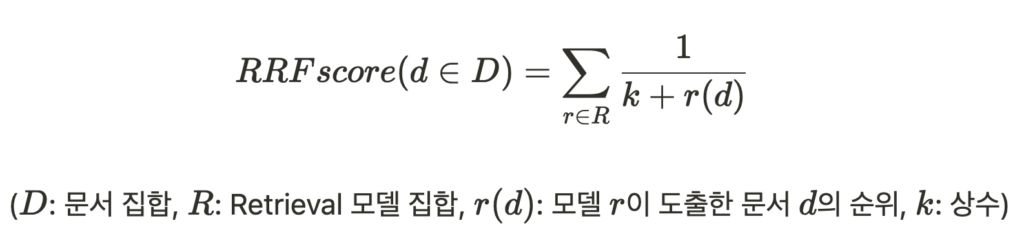
하지만 이러한 RRF 방식의 한계는 명확했습니다. 바로 Retrieval 모델을 여러 개 이용하는 경우 모델별 가중치를 사람이 직접 지정해줘야 한다는 점입니다. 저희는 콘텐츠 추천에 있어 인간의 개입을 최소화하고 싶었습니다. 또한 콘텐츠의 최신성과 같은 추가 피쳐를 반영한 랭킹 스코어를 매기고 싶었습니다. 따라서 여러 피쳐들을 고려하여 추천 콘텐츠 후보군에 점수를 부여해줄 수 있는 랭킹 모델을 도입하기로 했습니다.
Model Requirements
라이너에 도입할 랭킹 모델에 필요한 조건들은 다음과 같았습니다.
먼저, 추천 콘텐츠의 다양성이 보장되어야 했습니다. 유튜브나 핀터레스트의 홈 피드를 참고해보면, 페이지 새로고침을 할 때마다 노출되는 콘텐츠의 종류나 순서가 달라집니다. 라이너에서도 이와 같은 다이나믹한 느낌을 주기 위해 개인화된 콘텐츠에 고정된 랭크가 부여되는 것이 아닌, 확률적으로 변하는 랭크가 필요하다고 생각했습니다.
다음으로 콘텐츠의 최신성을 고려할 수 있어야 했습니다. 발행된지 오랜 시간이 지난 콘텐츠보다는 최근 발행된 콘텐츠의 매력도가 클 것이라고 생각했고, 이를 반영해줄 수 있는 랭킹 모델이 필요했습니다.
또 Impression Discounting 효과를 주고 싶었습니다. 링크드인의 논문 Modeling impression discounting in large-scale recommender systems(KDD ‘14)에서 아이디어를 얻었는데요. 유저에게 여러 번 노출되었는데 클릭이 일어나지 않은 콘텐츠의 경우 랭크를 낮춰줄 수 있어야 한다는 생각이 들었습니다.

Multi-Armed Bandit
위 조건을 만족하는 모델을 탐색하던 중 강화학습 분야의 멀티 암드 밴딧을 접하게 되었습니다. 멀티 암드 밴딧은 여러 개의 슬롯머신이 있을 때 어떤 손잡이를 내려야 수익을 최대화할 수 있을지를 반복적으로 결정하는 알고리즘인데요. 기존에 파악하지 못한 정보를 얻기 위해 새로운 손잡이를 당겨보는 Exploration과 기존의 경험과 정보를 바탕으로 수익률이 가장 좋은 손잡이를 선택하는 Exploitation을 적절히 조절해가면서 최적의 전략을 찾아나갑니다.
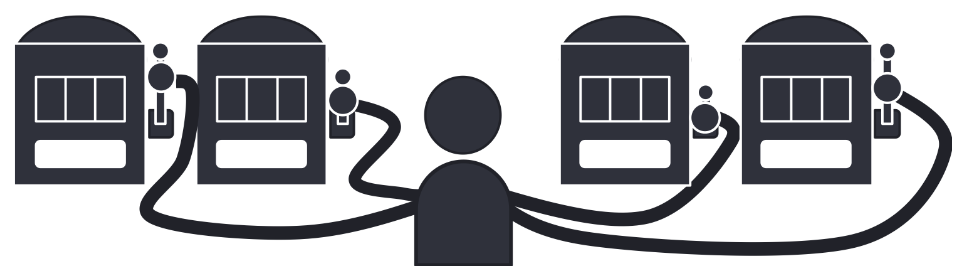
멀티 암드 밴딧을 추천시스템 관점에서 바라보면 여러 개의 아이템 중 유저에게 어떤 아이템을 추천해줘야 유저의 만족도(ex. 클릭률, 체류 시간, …)를 높일 수 있을지 결정하는 문제로 치환하여 생각할 수 있습니다. 대표적인 밴딧 알고리즘에는 Epsilon-Greedy, Upper Confidence Bound, Thompson Sampling 등이 있지만 저는 그 중 확률 분포를 이용한 알고리즘이면서 동시에 성능이 가장 좋다고 알려진 톰슨 샘플링을 랭킹에 활용해보기로 했습니다.
Thompson Sampling
톰슨 샘플링에서는 특정 아이템을 추천해주었을 때 유저가 해당 아이템을 클릭할 기대 클릭률을 베타 분포를 따르는 확률 변수로 봅니다. 아래 그림에서 보실 수 있듯이 Beta(⍺, β)에서 ⍺가 클수록 분포는 Left-skewed 형태가 되고, β가 클수록 분포는 Right-skewed 형태가 됩니다.
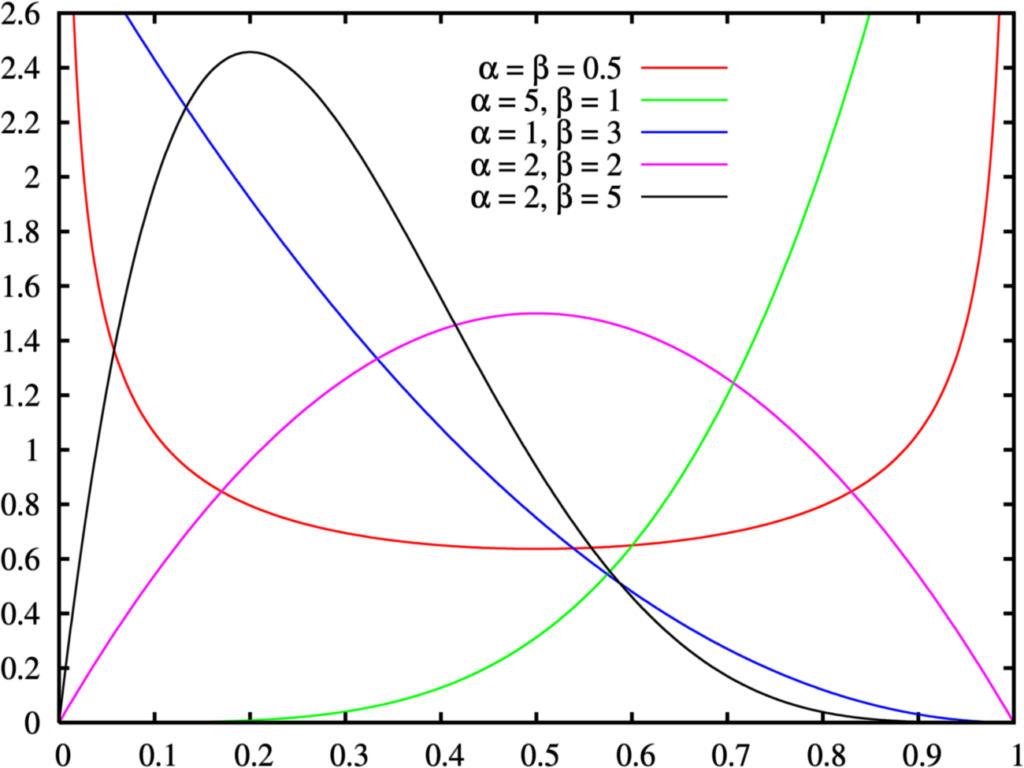
이렇게 아이템별로 만들어진 베타 분포에서 기대 클릭률 값을 추출하면 크기 순으로 K개의 아이템을 선정할 수 있는데요. 이 K개의 아이템을 유저에게 추천해주고 유저의 반응(ex. 클릭 여부)을 수집합니다. 그리고 유저로부터 받은 피드백을 바탕으로 ⍺, β를 조정하여 확률 분포를 업데이트 합니다. 유저가 클릭한 아이템의 경우 ⍺ 값을 키우고, 유저에게 노출되었지만 클릭하지 않은 아이템의 경우 β 값을 키우는 것입니다.
이 과정을 반복하다 보면 유저에게 실제로 인기 있는 아이템이 상위에 노출되고 유저가 클릭하지 않은 아이템들은 후순위로 밀리게 됩니다. 즉, 유저의 피드백을 바탕으로 알고리즘이 강화되어 클릭이 더 잘 발생할 만한 문서들 위주로 추천 피드를 재구성해줄 수 있는 것이죠.

Implementing Thompson Sampling-based Ranker
라이너의 추천 시스템에 톰슨 샘플링 기반의 랭커를 도입하기 위해서는 몇 가지 사전 작업이 필요했습니다.
먼저 문서별로 클릭 수와 노출되었지만 클릭되지 않은 횟수를 저장하고 실시간으로 업데이트 해줄 수 있어야 했습니다. 이를 위해 온라인 피쳐 스토어를 활용하기로 했는데요. 앞서 라이너 앱 Session-based Recommender 구축기에서 소개드렸다시피 라이너에서는 BigTable을 도입하여 실시간으로 피쳐들을 정제하고 넘겨받을 수 있게 되었습니다. 따라서 BigTable에 특정 문서의 플랫폼 별로 발생한 클릭 수, Non-클릭 수, 업데이트 된 시점을 저장해둘 수 있도록 구조를 만들었습니다.

다만 Non-클릭 수를 저장할 때 한 가지 고려할 사항이 생겼습니다. 한 화면에 하나의 콘텐츠만 보이는 라이너 앱과 달리, 웹의 추천 피드에서는 한 화면에 여러 콘텐츠가 보인다는 것이었습니다. 이 경우 노출이 되었지만 유저가 클릭하지 않은 콘텐츠 전부를 유저 마음에 들지 않은 콘텐츠라고 보긴 어려웠습니다. 따라서 웹의 경우엔 Cascading Assumption을 적용하여 유저가 N번째 콘텐츠를 클릭했다면, 1 ~ N-1 번째 콘텐츠들만 Non-클릭 수를 증가시키고 N+1 번째 이후 콘텐츠들에는 아무런 변화를 주지 않았습니다.
피쳐 스토어에 저장된 클릭 수와 Non-클릭 수를 불러와 베타 분포를 만들 때에도 생각해볼 점이 있었습니다. 베타 분포는 ⍺, β 값이 커질수록 폭이 좁아지는 경향이 있기 때문에 1씩 증가하는 클릭 수, Non-클릭 수를 그대로 파라미터로 사용하면 분포가 순식간에 뾰족해질 것이었습니다. 따라서 두 값에 적절한 가중치를 곱하여 스케일을 작게 만들어주는 작업이 필요했습니다. 또 클릭 수에 비해 Non-클릭 수가 훨씬 빠르게 증가할 것이기 때문에 두 파라미터에 서로 다른 가중치를 부여해주어야 했습니다. 따라서 저는 플랫폼별 하루 평균 클릭/노출 비율과 콘텐츠 하나당 하루 평균 몇 번 노출/클릭되는지를 고려하여 가중치를 설정했습니다.
그리고 저희는 일주일 전에 발생한 클릭과 오늘 발생한 클릭을 다른 것으로 취급해주고 싶었습니다. 클릭, Non-클릭이 발생한지 시간이 오래지나면 서서히 분포를 초기 상태로 되돌리고 싶었는데요. 피쳐 스토어에 마지막으로 클릭 수, Non-클릭 수가 업데이트된 시점을 저장하고 있었기 때문에 이를 불러와 Time Decaying을 적용해주었습니다.
마지막으로 유저와 인터랙션이 없었던 문서의 ⍺, β 초기값을 무엇으로 둬야 할지에 대한 고민도 필요했습니다. 원래 톰슨 샘플링에서는 모든 아이템에 대해 기본적으로 Beta(1, 1)로 초기화를 시켜주는데요. 이 경우 분포는 수평선 모양이 되어 [0, 1]의 값을 랜덤 추출하는 것과 같은 셈이 됩니다. 저희도 이렇게 균등 분포에서 확률 변수를 추출하는 것에 동의하여 인터랙션이 없었던 문서의 베타 분포 파라미터를 ⍺=1, β=1로 초기화시켜주었습니다. 나아가 DoorDash에서 아이템 그룹마다 초기 분포를 다르게 주어 Warm-start 밴딧을 만든 사례를 참고하여 최근 N일 이내에 생산된 콘텐츠라면 ⍺에 어드밴티지를 주었고, 이를 통해 콘텐츠의 최신성을 챙기고자 했습니다.
appAlpha = appClickCount * AppAlphaWeight
webAlpha = webClickCount * WebAlphaWeight
appBeta = appNotClickCount * AppBetaWeight
webBeta = webNotClickCount * WebBetaWeight
alpha = 1 + (appAlpha+webAlpha)*math.exp(-timeDiff/TimeDecay)
beta = 1 + (appBeta+webBeta)*math.exp(-timeDiff/TimeDecay)
if isRecentDocument[DocumentId]:
alpha += WarmStartAlphaIncrement
rankingScoreMap[DocumentId] = beta(alpha, beta).rvs(1)Model Performance
이렇게 라이너의 추천 시스템에 강화학습 기반의 랭킹 모델을 성공적으로 도입할 수 있었습니다. 배포 후 랭킹 모델의 성과를 측정하기 위한 방법을 고민해보았는데요. 추천 피드에서 Rank N 이내 콘텐츠의 클릭 비중을 배포 전과 비교하여 트래킹하고 있습니다. 아직 지표상으로 큰 차이는 없지만 배포 전에 비하면 더 높은 순위 콘텐츠의 클릭 비중이 증가했음을 확인할 수 있습니다. 앞으로 밴딧 알고리즘이 강화되면서 유저가 클릭할 만한 양질의 콘텐츠들을 더 위쪽으로 끌어올려줄 것이라고 기대하는 바입니다.

Future Work
강화학습 기반의 랭커를 도입함으로써 유저들의 피드백을 받아 추천 모델의 성능이 더욱 향상되는 Human-AI Co-Learning이 가능해졌습니다. 하지만 아직 개선의 여지는 많이 남아있습니다.
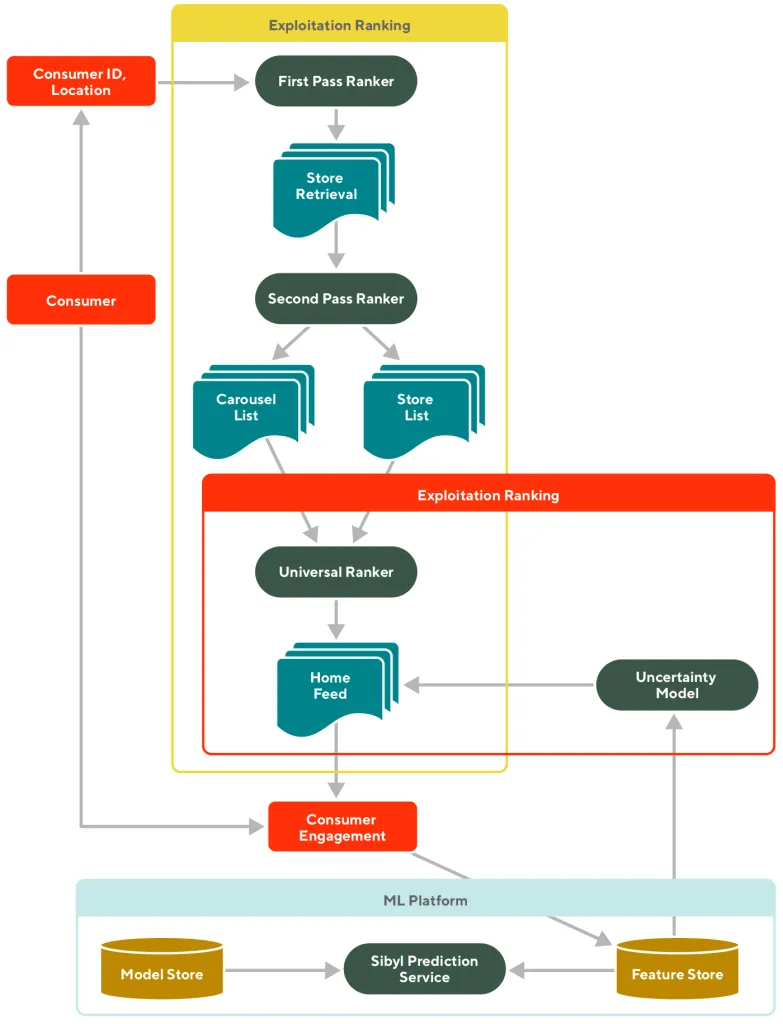
현재 예정된 Next Step은 톰슨 샘플링을 보조해주는 Pre-Ranker를 도입하는 것입니다. 톰슨 샘플링은 유저와 아이템의 인터랙션을 기반으로 점점 강화되지만 아직 유저와 아이템 자체의 피쳐들을 고려해주지는 못하고 있습니다. 이를 개선하기 위해선 Neural Ranker를 도입하여 콘텐츠별로 고정된 스코어를 도출하고, 이를 기반으로 만들어진 베타 분포에서 확률적인 스코어를 도출하는 아이디어를 적용해볼 수 있습니다. 실제로 DoorDash에서도 딥러닝 기반의 Universal Ranker와 멀티 암드 밴딧의 UCB 알고리즘을 결합하여 홈 피드 추천을 제공하고 있으며, 저희도 이와 유사한 구조를 만들어보려고 합니다.
Conclusion
라이너는 추천에 있어서 인간의 개입을 최소화하고 기술력을 중심으로 유저에게 개인화된 콘텐츠를 제공해주기 위해 노력하고 있습니다. RRF 기반의 랭킹 알고리즘을 밴딧 알고리즘으로 대체한 것 뿐만 아니라 기존에 콘텐츠의 퀄리티를 컨트롤하기 위해 만들어두었던 도메인 기반의 화이트 리스트를 없애고 품질 판단 모델을 만든 것도 같은 이유 때문이었습니다. 유저에게 더 나은 콘텐츠를 추천해주기 위해 Multi-stage 추천 시스템의 각 단계를 고도화시키는 작업은 앞으로도 계속될 예정입니다.
저희가 아직 풀어야 할 문제는 많습니다. 함께 문제를 해결하면서 성장하고자 하시는 분이 있다면 언제든지 연락주시면 감사하겠습니다. 앞으로도 라이너에 많은 관심과 응원 부탁드리며, 블로그를 통해 다음에 소개드릴 이야기들도 기대해주세요😀