컨텐츠 기반 필터링 구축기: MiniLM, ScaNN 그리고 TFServing

안녕하세요, 머신러닝 엔지니어 카터입니다. 지난 번에는 외부로부터 추천 아이템이 축적되는 라이너가 컨텐츠 퀄리티 컨트롤을 위해 필터링 로직을 어떻게 가져가고 있는지에 대한 소개를 드렸습니다. 이번 글에서는 라이너가 컨텐츠 기반 필터링을 어떻게 구축하여 추천 시스템에 활용하고 있는지에 대해 소개드리고자 합니다!
ANN과 ScaNN
라이너는 수백만 개 문서 중 사용자에게 추천할 만한 문서 수백 개를 추리기 위한 작업을 Approximate Nearest Neighbor Search (이하 ANN)를 통해 해결하고 있습니다. ANN은 브루트 포스로 입력 문서와 모든 후보 문서 간 유사도를 계산해 줄세우기를 하는 작업이 시간 복잡도 상 불가능한 상황에 반드시 활용되는 기술입니다. 때문에 ANN을 위한 수많은 패키지들이 오픈 소스로 공개되어 있으며, Spotify (Annoy), Facebook (faiss), 카카오 (N2) 등 다양한 테크 기업에서 자신들만의 ANN 패키지를 공개 및 활용하고 있습니다.
오늘 글의 주제인 Scalable Nearest Neighbors (이하 ScaNN)은 2020년 ICML, Accelerating Large-Scale Inference with Anisotropic Vector Quantization 논문을 통해 Google이 새로이 공개한 ANN 알고리즘이자 패키지입니다.
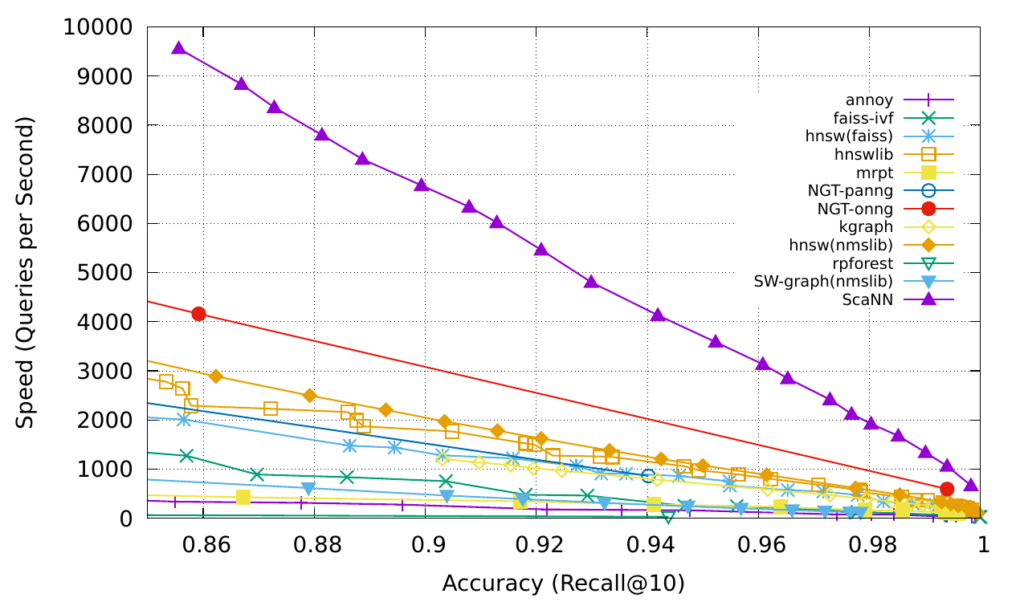
ScaNN은 실험을 통해 Speed-Recall 트레이드 오프에서 다른 알고리즘들을 압도하는 모습을 보여주었으며, 공개되자마자 ANN 알고리즘들의 경쟁의 장인 ANN Benchmarks 내 대부분 벤치마크에서 최상위 성능을 기록하기도 했습니다. 또한 Tensorflow 구현체 패키지를 오픈 소스로 공개해 ANN 생태계에 기여하기도 했습니다.
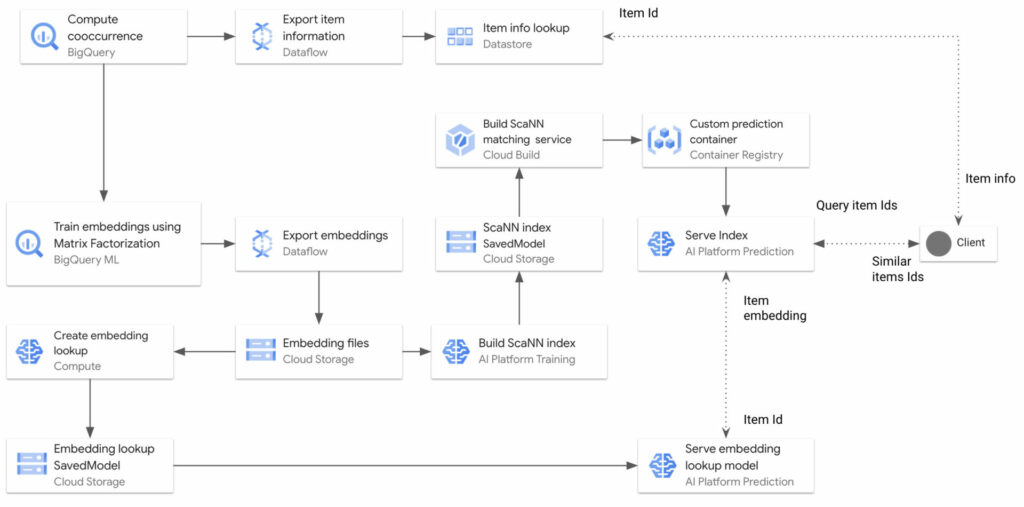
22년 2월 기준, ScaNN은 Google Research 레포지토리에서 관리되고 있는 리서치 프로젝트입니다. 그러나 Google Cloud Platform에서 ScaNN을 적용한 다양한 예제들이 생겨나고 있으며, Tensorflow Recommenders (이하 tfrs)와 같은 프로젝트에서 ScaNN을 네이티브로 도입하려는 움직임을 보아 곧 리서치 레벨을 졸업할거라 예상되고 있습니다.
Content-based Filtering을 위한 Embedding
본격적으로 ScaNN을 구축하기 앞서, 라이너가 임베딩 모델과 아이템 매트릭스를 어떻게 얻고 있는지 소개를 드리겠습니다. 라이너에는 한국어, 영어, 일본어, 중국어, 힌디어 등 수많은 언어로 작성된 문서가 적재되고 있습니다. 따라서 임베딩을 위해 반드시 멀티링구얼 모델을 활용해야 한다는 제약이 있습니다. 이를 위해 USE, LASER, LaBSE, XLM-R 등 여러 모델을 비교해보았고, 성능 및 의존성 그리고 지원 언어 등의 조건을 고려했을 때 XLM-R을 사용하는 것이 가장 바람직하다는 결론에 이르렀습니다.
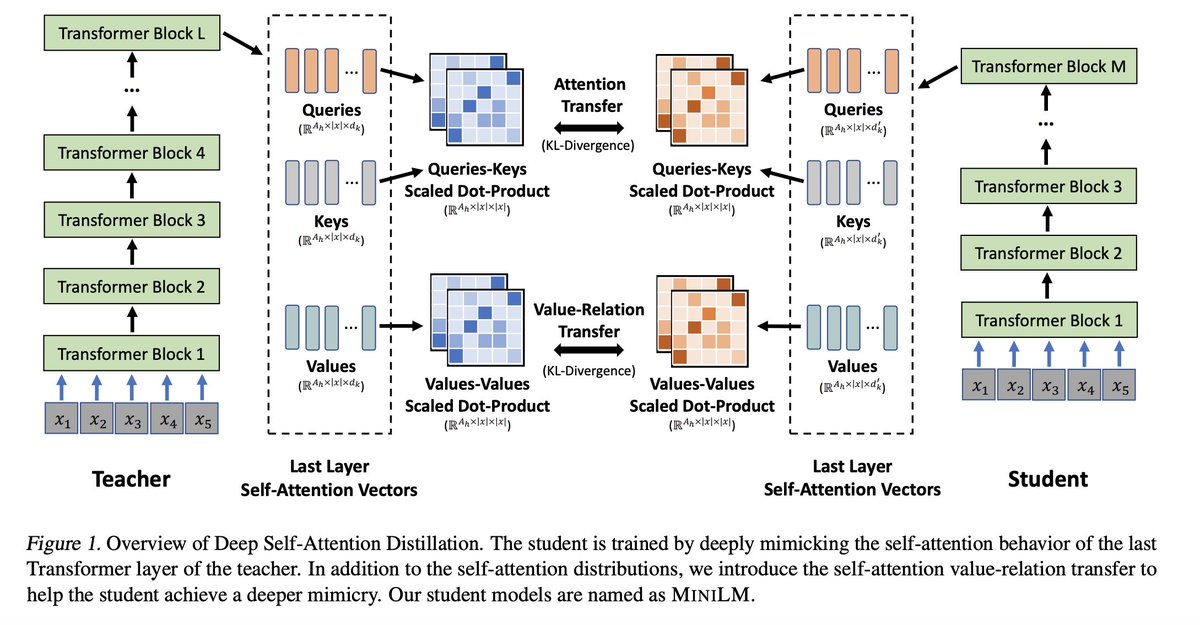
그러나 XLM-R의 가장 큰 문제는 모델이 너무 무겁다는데에 있습니다. 아무리 좋은 성능을 지녔더라도 매번 엄청난 컴퓨팅 자원을 요구하는 XLM-R은 프로덕션 레벨에서 활용하기에는 무리가 있습니다. 때문에 Microsoft의 Multi-lingual MiniLM 모델로 눈을 돌리게 되었습니다. Multi-lingual MiniLM은 XLM-R의 크기를 줄이면서도 성능은 최대한 보존해보자는 목적을 가지고 시작된 프로젝트로, Teacher Model의 Self-Attention (특히 마지막 레이어)을 모방하는 방식으로 distill이 진행됩니다.

트랜스포머 기반 모델에서는 Self-Attention 연산이 가장 중요하기 때문에, 마지막 레이어의 Self-Attention 연산을 잘 모방하는 것만으로 히든 디멘션, 레이어 갯수 등 모델 크기를 키우는데 영향을 주는 하이퍼 파라미터 값을 크게 줄일 수 있었고, 실제로 가볍지만 성능의 감소는 크게 없는 좋은 Student Model을 얻게 되었다고 합니다.
이렇게 선정된 임베딩 모델이 학습하게 될 데이터는 라이너 사용자의 하이라이트 세션 데이터입니다. 먼저, 라이너 사용자들의 하이라이트 로그 데이터를 읽어와 30분 간격으로 세션을 나눈 후, 세션 내 인접 문서들을 Positive Pair 로 분류하였습니다. 그리고 다른 사용자의 세션 내 문서를 임의로 추출해 Negative Pair 로 짝을 이루도록 하였습니다.
동일 세션 내에는 유사한 주제의 문서들이 위치할 것이며, 서로 다른 사용자들의 세션에서 Negative Item을 추출하는 것이 완전 임의 추출보다 낫다는 판단 하에 진행한 훈련 데이터 처리 전략이며 추후 Negative Sampling은 더 개선되어야 합니다.
이렇게 얻어진 학습 데이터를 가지고 Sentence Transformers 패키지를 활용해 임베딩 모델의 학습을 진행합니다. 패키지 내 예제가 잘 소개되고 있기 때문에 훈련 관련 이야기는 따로 언급하지 않지만, 학습 모델 저장이 EmbeddingSimilarityEvaluator 클래스의 main_similarity 기준으로 이루어지기 때문에 특별히 사용하는 메트릭이 있는 경우, 반드시 지정을 해주어야 합니다. 저는 ScaNN 인덱스 구축 시, Dot Product 기준으로 트리를 생성하게 하기 위해 DOT_PRODUCT의 옵션을 주었습니다.
임베딩 모델의 학습을 마친 후에는, 학습에 사용된 모든 문서들을 모델로 인코딩하여 매트릭스 파일을 저장하도록 하였고, 최종적으로 약 (1,500,000 x 384)의 매트릭스를 얻게 되었습니다.
ScaNN 학습과 배포
ScaNN을 가장 손쉽게 학습하는 방법은 tfrs 내 ScaNN 클래스를 사용하는 것입니다. 앞서 언급했듯, tfrs는 ScaNN을 프로젝트에 네이티브로 도입하려 하고 있습니다. 때문에 tfrs 내 구현체를 활용하면 ScaNN을 모듈로 쉽게 활용할 수 있습니다. 예제에서는 쿼리 모델과 TopK 모델을 하나로 합쳐 모델로 활용하지만, 라이너는 임베딩 모델 서버와 TopK 모델 서버를 따로 관리하기 때문에 ScaNN만 학습 및 배포하도록 하였습니다.
먼저 아래와 같이 ScaNN 모델을 초기화합니다. 앞서 Sentence Transformers 학습 시, 어떤 지표를 main_similarity로 설정할 것인지 정해주어야 한다고 한게 바로 아래 distance_measure 때문입니다. 학습을 통해 최적화 된 유사도를 기반으로 인덱스를 빌드하는 것이 바람직하기 때문에 모델 학습과 인덱스 빌드 시, 유사도 지표를 통일시켜주어야 합니다. ScaNN이 지원하는 모든 Distance Measure 는 링크에서 확인하실 수 있습니다.
또한 ScaNN 인덱스 구축을 위해 다양한 인자들을 입력해주어야 하는데, 시나리오에 따라 값을 조정하기 위한 가이드라인을 공식 문서를 통해 제공해주고 있습니다. 여기서 ScaNN의 아쉬운 점이 나오는데, 아직 리서치 프로젝트이다보니 faiss 처럼 문서가 아주 친절하지는 않습니다.
METRIC = "dot_product"
scann = tfrs.layers.factorized_top_k.ScaNN(
distance_measure=METRIC,
k=NUM_NEIGHBOURS,
num_leaves=num_leaves,
num_leaves_to_search=NUM_LEAVES_TO_SEARCH,
num_reordering_candidates=REORDER_NUM_NEIGHBOURS,
)모델 초기화 이후에는 미리 구워 놓은 아이템 매트릭스를 모델에 넣어 인덱스를 생성해줍니다. 아이템 매트릭스는 Numpy, tf.Tensor 모두 활용할 수 있습니다.
scann.index(embeddings)이제 다음이 중요한데 인덱스 생성 후, ScaNN 모듈이 임의의 문서에 대해 추론을 한 번 거치도록 합니다. 이는 모델의 입출력 Shape, Type 등을 모델 내 Signature 로 기록하기 위함입니다. 추론 이후에는 일반적인 모델을 저장하는 것과 같이 ScaNN 모델을 저장해줍니다.
_ = scann(embeddings[0])
tf.saved_model.save(
scann,
output_dir,
options=tf.saved_model.SaveOptions(namespace_whitelist=["Scann"]),
)
마지막으로 ScaNN을 프로덕션에 활용하기 위해서는 위 과정을 통해 학습된 모델을 배포해주어야 합니다. ScaNN은 커스텀 TF Ops를 활용하여 작성되었기 때문에 일반적인 TFServing 도커 파일로 배포하기가 까다롭습니다. 때문에 커스텀 TF Ops가 호환되는 도커 파일을 ScaNN에서 직접 제공해주고 있습니다. 해당 도커 파일과 앞서 빌드한 인덱스를 활용하면 TFServing 서버를 손쉽게 배포할 수 있습니다.
서버 배포 후, CURL로 아래와 같이 metadata 요청을 보내보면 입출력 Shape, Type 등이 정의된 Signature 가 모델에 잘 기록되어 있는 것을 확인할 수 있습니다. input_1은 실수로 구성된 벡터, output_1은 실수로 반환되는 distance, output_2는 정수로 반환되는 인덱스입니다.
$ curl GET <http://localhost:9090/v1/models/index/metadata>
"metadata": {"signature_def": {
"signature_def": {
"serving_default": {
"inputs": {
"input_1": {
"dtype": "DT_FLOAT",
"tensor_shape": {
"dim": [
{
"size": "-1",
"name": ""
}
],
"unknown_rank": false
},
"name": "serving_default_input_1:0"
}
},
"outputs": {
"output_2": {
"dtype": "DT_INT32",
"tensor_shape": {
"dim": [],
"unknown_rank": true
},
"name": "StatefulPartitionedCall:1"
},
"output_1": {
"dtype": "DT_FLOAT",
"tensor_shape": {
"dim": [],
"unknown_rank": true
},
"name": "StatefulPartitionedCall:0"
}
},
"method_name": "tensorflow/serving/predict"
},
..
}
}
또한 아래와 같이 서빙 프로세스에 요청을 날릴 수도 있습니다. 참고로 models/index는 TFServing을 띄우는 과정에서 직접 지정해준 모델 경로와 모델명입니다. 따라서 고정 값이 아니며, v1, predict 등은 TFServing이 지정하는 고정 값입니다.
curl -d '{"inputs": [0.5, ..., 0.5]}' -X POST <http://localhost:9090/v1/models/index:predict>
만약 k8s를 활용해 컨테이너 프로세스를 관리한다면, 특정 프로세스가 잘 동작하고 있는지 확인하기 위해 readinessProbe 옵션을 통해 Health Check를 요청하게 할 수 있습니다. TFServing의 경우, Model Status API를 통해 해당 기능을 지원하므로 아래와 같이 옵션을 설정해주시면 됩니다.
readinessProbe:
httpGet:
path: /v1/models/index
port: 9090
scheme: HTTP
마치며..
이번 글에서는 라이너가 컨텐츠 기반 필터링 시스템을 어떻게 구축하여 활용하고 있는지에 대해 이야기를 담아보았습니다. 그리고 추천 시스템에 익숙하신 분들이라면 글을 통해 소개한 시스템은 추천 시스템을 구성하는 여러 컴포넌트 중 한 축에 불과하다는 것을 잘 아실거라 생각합니다.
이어질 글들을 통해 협업 필터링, 토픽 모델링, MLOps 등 더 다양한 컴포넌트들에 대한 이야기를 함께 공유하고 싶습니다. 현재 언급한 모든 주제에 대한 개발이 진행되고 있기 때문에 가까운 시일 내에 관련 이야기를 추가적으로 공유드릴 수 있을 것 같습니다.
저에 대한 이야기를 잠깐 하자면, 저는 라이너에서 본투비 글로벌로 시작한 프로덕트이기에 겪는 다양한 시행착오 속에서 매일 매일 성장을 경험하고 있습니다. 머신러닝 엔지니어로 이만큼 챌린징한 일을, 이만큼 많은 데이터를 가지고, 이렇게 마음 맞는 동료들과 함께 풀 수 있는 기회가 시장에 많이 없다는 것을 너무나도 잘 알고 있습니다.
그렇기에 라이너에서 더 많은 좋은 분들과 더 볼드한 문제를 해결하고 싶어요! 저는 물론이고, 라이너 팀 모두 좋은 분들과 함께 더 큰 문제를 풀며, 글로벌 시장에서 싸울 준비가 되었으니 혹 글을 읽으며 흥미가 생기셨다면 부담없이 연락주시면 감사하겠습니다 ✌️
WANTED: 데이터와 기술로 라이너를 더 단단하게 만들어 주실 분
라이너는 전 세계 500만 사용자와 함께 하는 하이라이팅 기반 정보 탐색 서비스입니다. 기존 텍스트 하이라이트에 YouTube 하이라이트까지 등에 업은 라이너에는 매일 텍스트와 동영상 등 다양한 모달리티의 컨텐츠에 대해 수백만 건의 로그 데이터가 쌓이고 있습니다.

라이너는 데이터를 활용해 사용자가 원하는 발전을 위해 소비해야 할 컨텐츠를 큐레이팅 해주는 역할을 대신해주고자 합니다. 라이너가 해결하고자 하는 문제를 풀어줄 모델링을 하고 싶은 머신러닝 사이언티스트, 추론 엔진을 500만 사용자에게 쾌적하게 서빙해보고 싶은 머신러닝 엔지니어, 외에도 데이터를 과학적으로 혹은 엔지니어링적으로 잘 다루시는 모든 분들을 기다리고 있습니다!