유해 키워드 필터링 문제와 해결
겪은 문제
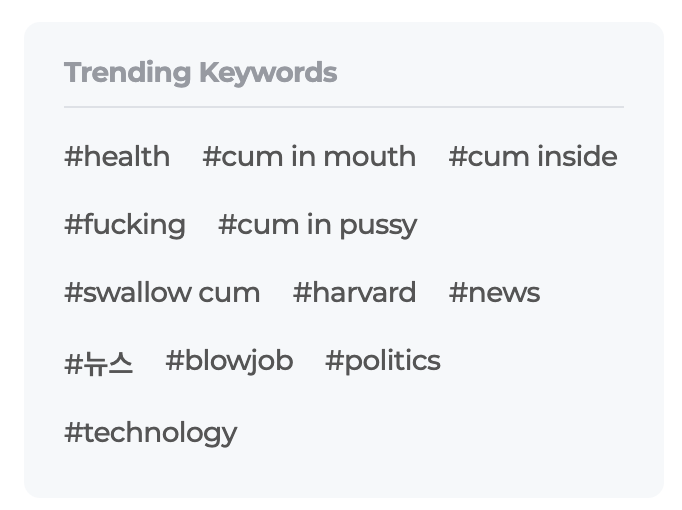
라이너 메인 홈에 필터링이 반드시 필요한 콘텐츠들이 뜨기 시작했습니다. 영어권 유저가 아니더라도 홈에 접속하는 유저들 모두에게 눈쌀을 찌푸리게 할 정도의 내용이었습니다.
문제의 원인
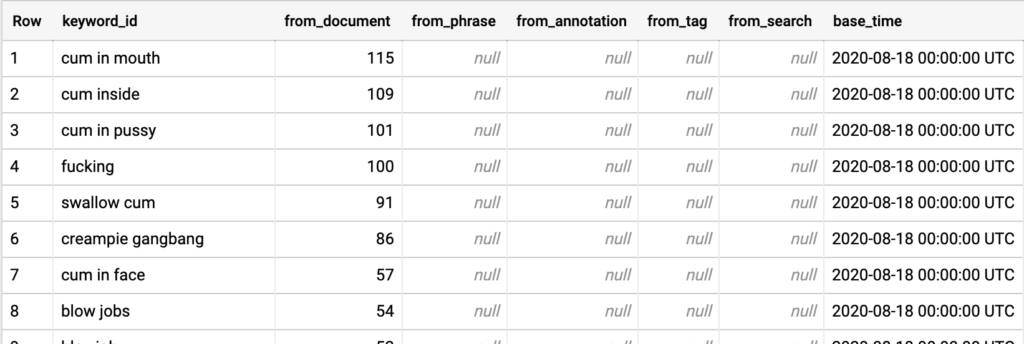
문제의 원인은 소수의 특정 유저가 유해 사이트에서 페이지들을 마구잡이로 스크랩했기 때문이었습니다. LKS(Liner Knowledge System)에서는 스크랩되는 페이지의 메타 태그를 트렌딩 키워드 후보군으로 집계시키고 있습니다. 때문에 간혹 특정 유저가 이상치 수준으로 스크랩하는 경우 해당 문서들의 키워드가 트렌딩으로 잡힐 수 있습니다. 이 경우 유해 문서의 메타 태그가 유해어로 꼼꼼히 채워져 있었기 때문에 유해 단어들이 모두 카운팅 되면서 트렌드 영역에 나타나게 되었습니다.
해결
키워드 카운팅 방법 변경
해당 유해 사이트를 마구잡이로 스크랩한 유저가 소수였기 때문에, 트렌딩 키워드 카운팅 방식을 고유한 유저의 수로 한정하는 방식으로 해결하려 했습니다. 즉 한 유저가 아무리 많이 스크랩을 하더라도, 1로 카운팅하는 방식입니다. 라이너 유저의 대부분이 건전하고 고급스러운 콘텐츠를 소비하고 있기 때문에 이 정도의 대처면 충분할 것으로 판단했습니다.
원래의 카운팅 방식은 아래와 같았습니다.
target_ids는 키워드가 부여되는 리소스의 ID입니다.- 유해 콘텐츠의 경우, 유해어(keyword)가 유해 콘텐츠(target_id)에 붙여집니다.
- 그리고 이렇게 붙여지는 상황(source_type –
from_document)을 모두 카운팅합니다.
WITH keyword_data AS (
SELECT keyword_id, source_type, target_ids
FROM user_data.user_keyword_journey,
UNNEST(user_keyword_journey.keywords) keyword_id
WHERE '{start_time}' <= created_at
AND created_at < '{end_time}'
)
...
이것을 고유한 user_id의 수를 카운팅하는 방식으로 변경했습니다.
바뀐 방식으로 인하여 유해어(keyword)를 스크랩(source_type = from_document)한 유저의 수를 카운팅하게 됩니다.
WITH keyword_data AS (
SELECT keyword_id, source_type, COUNT(DISTINCT user_id) cnt
...
GROUP BY keyword_id, source_type
)
...
배치 작업을 다시 돌려서 새로운 산정 방식으로 통계 테이블을 변경하였습니다. 이후 변경된 값이 적용되자 유해어들이 트렌딩에서 사라졌습니다.
다시 나타난 유해어
카운팅 방식을 바꾼 바로 다음날, daily 통계가 돌아간 이후 유해어 중 하나가 트랜딩 키워드에 노출되었습니다. 변경된 방식에 의하면 사용자의 절대적인 수가 많아지지 않는 이상 트렌딩에 잡힐 수 없는 상황이었습니다. 무엇이 문제였을까요?
다시 만난 문제의 원인
문제의 포인트는 시스템의 특성 두 가지에서 비롯되었습니다.
- 트렌딩 키워드의 카운팅은 최근 1주일을 기준으로 합니다.
- 스크랩되는 페이지의 종류가 sparse합니다.
이러한 특성이 다음과 같은 문제의 원인을 촉발하게 되었습니다.
- 페이지 종류가 sparse해서 카운팅되는 절대 수치가 크지 않았다.
- 또한 1주일치 카운팅에서 비-유해어가 많이 스크랩되었던 날들이 빠지며 유해어에게 수치가 밀렸다.
근본적으로는 유저의 수가 늘면서 자정작용을 기대하고 싶었지만 페이지 종류가 워낙 다양하고 유저들의 성향 또한 다양하기 때문에 언제든 발생할 수 있는 일이라고 판단하였습니다.
다시 문제 해결
유해어 사전을 만드는 것으로 대응했습니다. 카운팅이 높게 잡히는 유해어들을 추출하고 공통 문자열을 찾아내어 블랙리스트를 만들었습니다.
사전을 만들어서 관리하는 방식은 지속적으로 리소스가 들기 때문에 달갑지 않았지만 개발 리소스가 별로 많지 않은 상황에서는 효율적이었습니다.
이로써 이제 더 이상 트렌딩 키워드에서는 유해어를 볼 수 없게 되었습니다.
추후 과제
1. 사전 언어 추가
- 영어 / 한국어 외 다른 언어에 대해서도 사전이 필요한 상황입니다.
2. 유해어 판단 고도화
- 규칙-기반 방식이 아니라 언어 모델 등을 활용한 방식을 통해 유해어 방지 커버리지를 높이는 방안을 생각해보았습니다.
3. 의미 기반 키워드 카운팅
- 규칙-기반 방식을 유지하는 경우 유해어를 그루핑할 수 있다면 리소스 절약에 도움이 될 수 있다고 판단했습니다.
- 또한 비-유해어에 대한 카운팅을 높일 수 있을 것이라 판단했고 이는 결국 트렌딩 키워드 포착 품질에도 직접적 영향을 준다고 생각했습니다.
- 다만 결국 유해 콘텐츠를 소비하는 유저가 많아진다면 이 역시 소용이 없을 것입니다.
마무리
트렌딩 키워드의 카운팅 방식을 바꾸어 시스템적으로 자정작용이 작동하도록 구현했지만 어떤 유저가 어떤 내용을 언제 스크랩할지 예측할 수 없는 상황에서 결국에는 유해어에 대한 판단과 필터링이 필요하다는 것을 알 수 있었습니다. 현재는 사전 기반의 규칙을 이용하고 있지만 추후에는 이를 고도화하여 유해 콘텐츠가 플랫폼에 얼씬도 못하도록 하고 싶습니다.